
Custom data in your website audit
Content extraction allows you to customize the output you get from Sitebulb's crawler, and include specific datapoints that you need to help you make better decisions. You can use it to help determine popular content by scraping comment counts, assign author names to URLs from a blog, or count the number of products in each category on an ecommerce store.
Content search enables you to identify pages which contain specific words or phrases, which is a crucial feature for rebranding/migration exercises, and extremely useful for topic modelling and finding internal linking opportunities.
Sitebulb's extraction setup is a cinch for beginners to get the hang of, whilst also offering extremely advanced configuration options for more experienced users.
Taking the pain out of content extraction
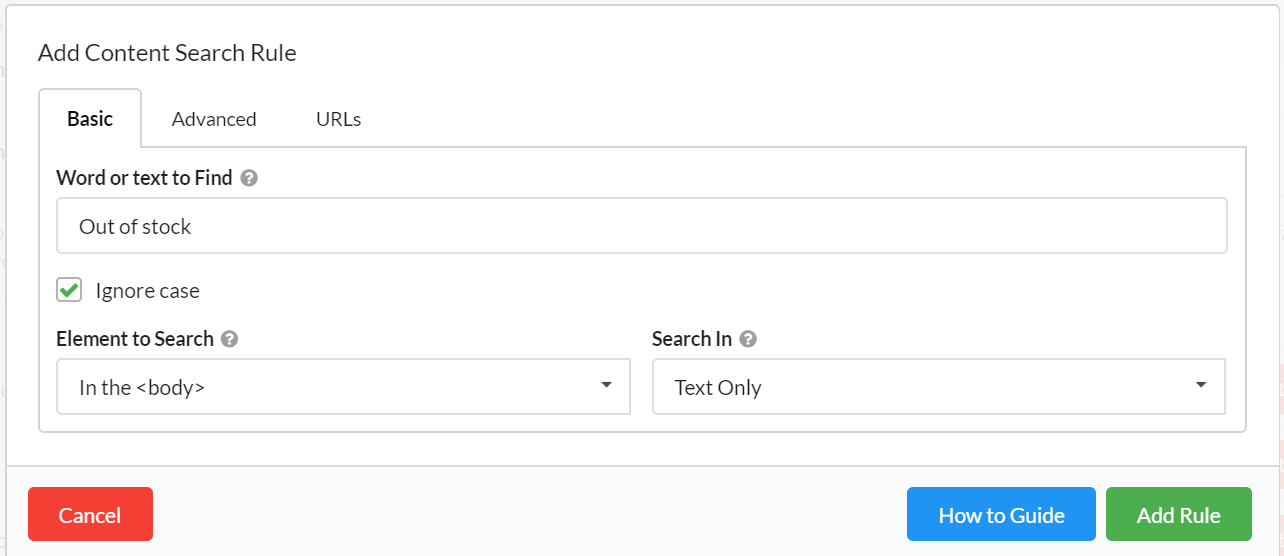
If you're familiar with custom extraction on other crawler tools, you'll know how frustrating it can be to set it up correctly. Sitebulb is designed to remove all these frustrating pain-points, with an intuitive system that does the heavy lifting for you:
- Load in a test URL into the visual selector window (also works with JavaScript frameworks).
- Point and click the element you want to scrape.
- Give the datapoint a meaningful name.
- Check the 'Test' tab to ensure it is working as you expect.
This means it works on any website you throw at it. It means you don’t need a degree in advanced Regex to figure out what selector to choose. And it means you don’t need to crawl the website 37 times in order to test your selectors.

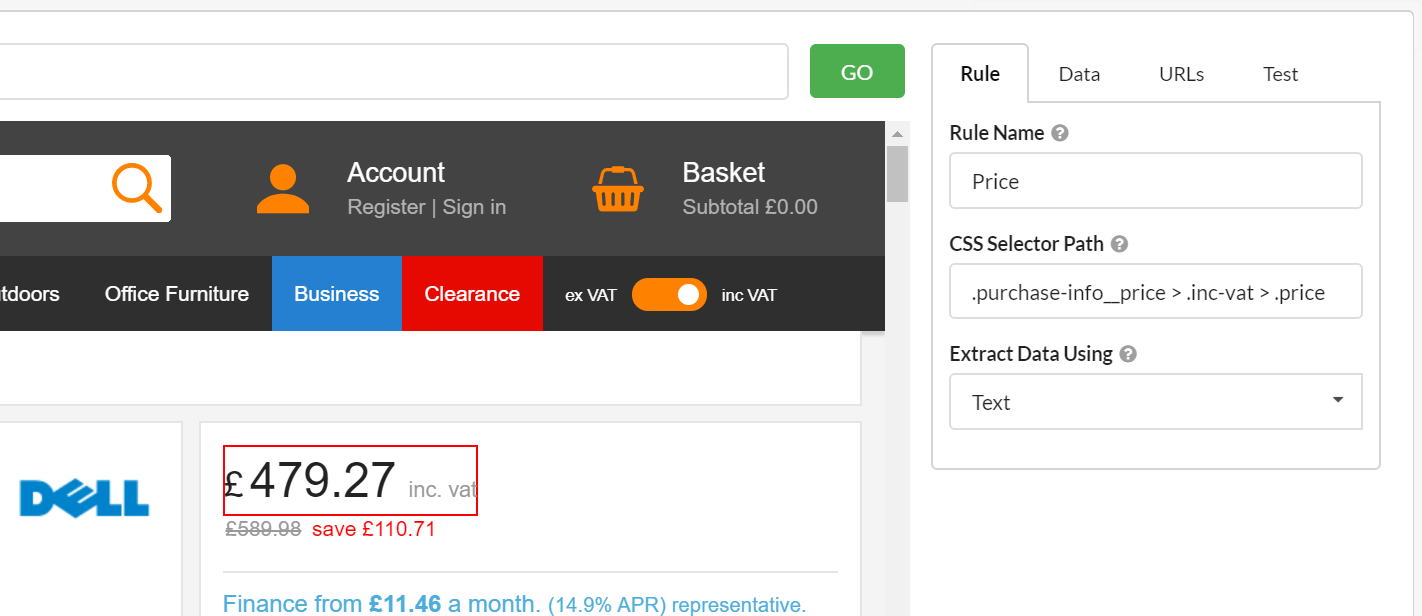
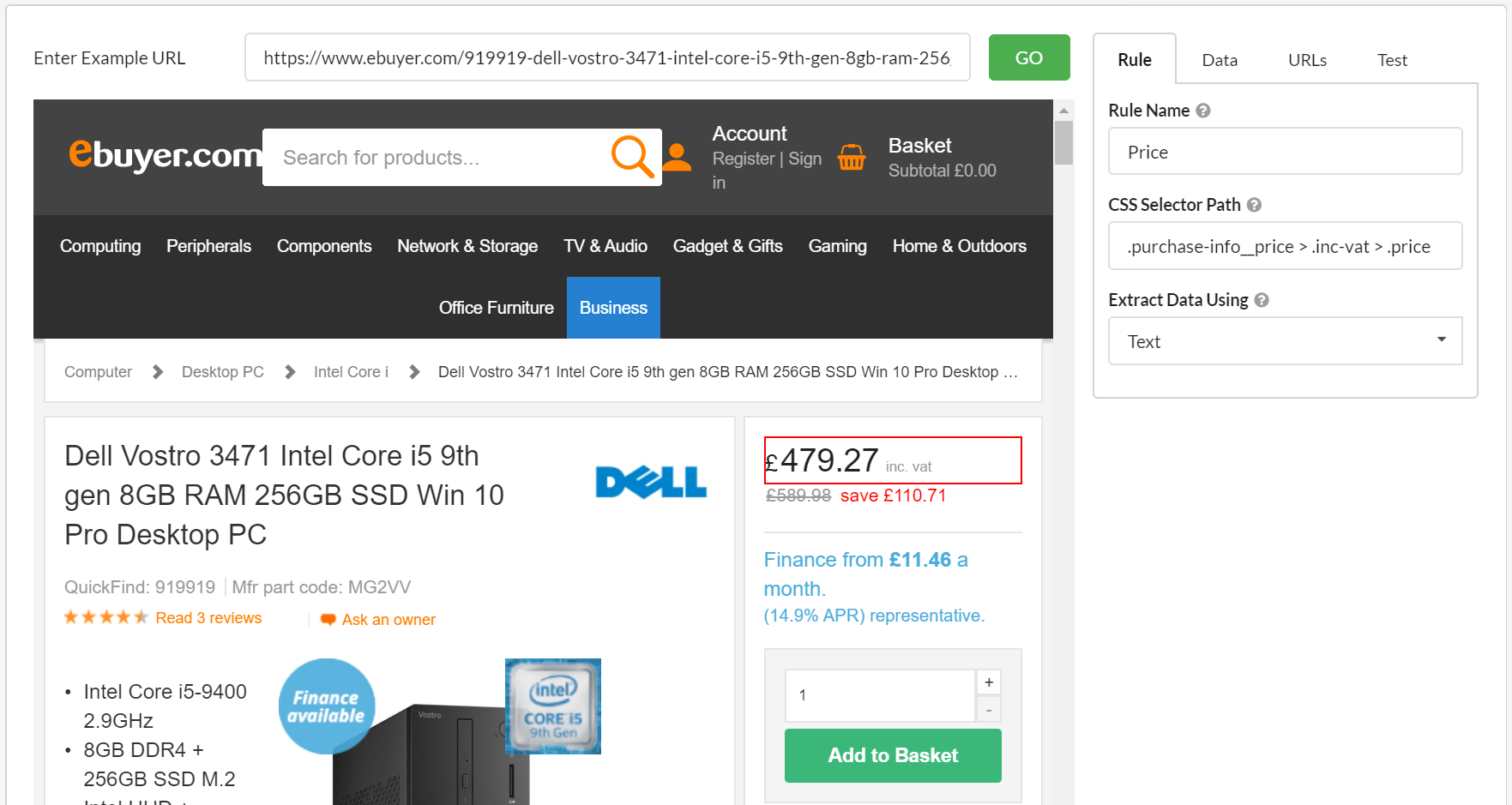
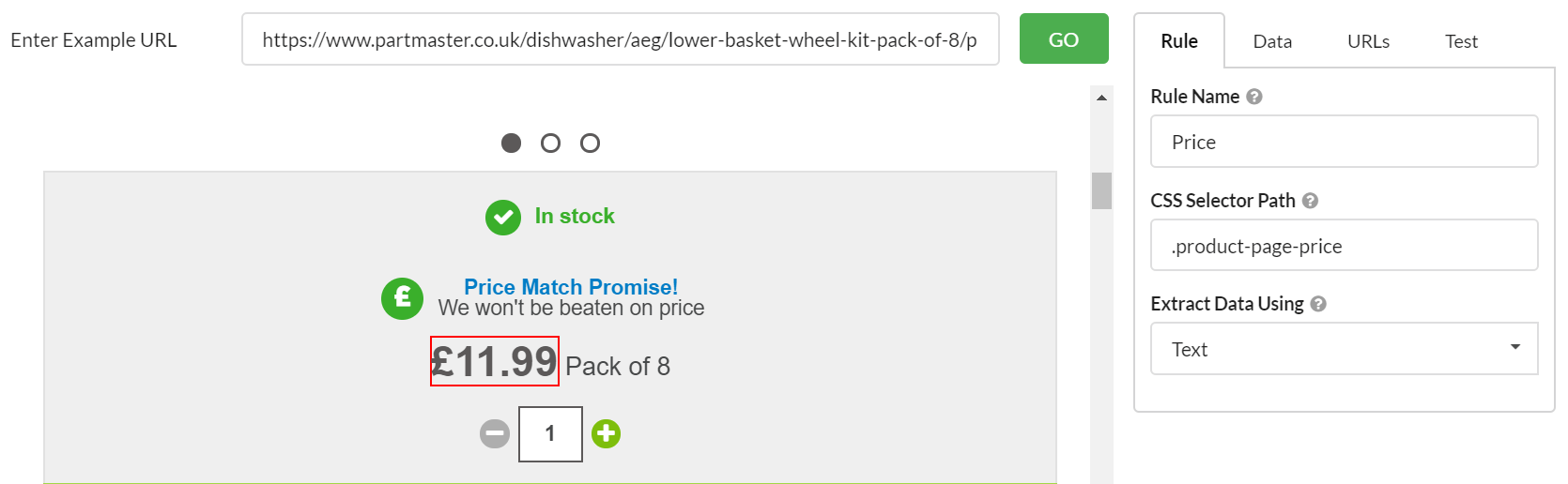
Point-and-click interface
See a piece of data you'd like to extract, then just point-and-click, and Sitebulb will choose the correct CSS selector for you.
To perform content extraction on other crawler tools, divining the correct CSS selector can be a bit of a mission, involving digging around in Google Chrome DevTools and hoping you have got the right one.
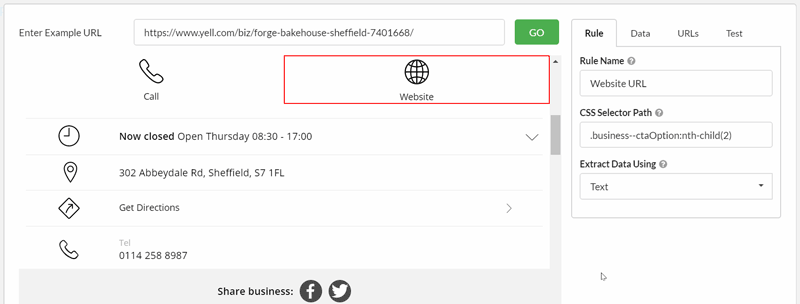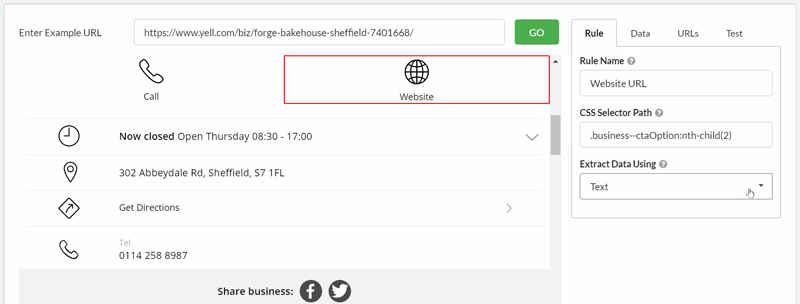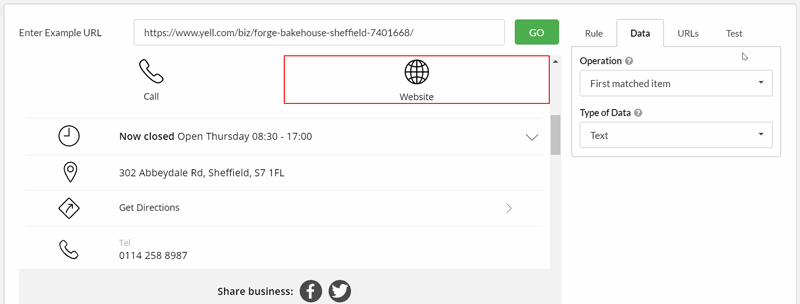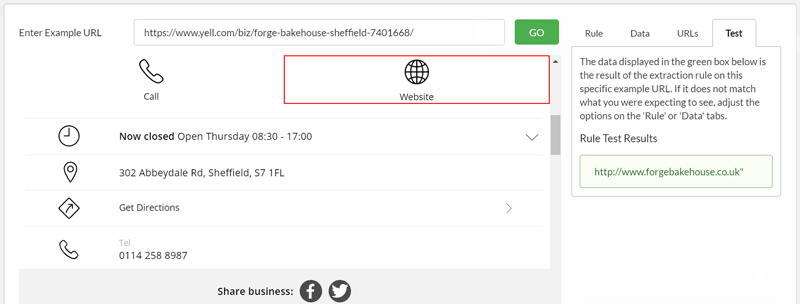
Test without crawling
The handy 'Test' tab means you can ascertain the result of your extraction setup without running a crawl, which makes a significant time saving.
The test feature allows you to tweak different extraction options to ensure you have picked the right selector and data type, or load in different URLs to ensure that the extraction works across different pages.
Advanced extraction options
Extraction is not just restricted to simple scraping, you can also perform operations such as a count, or checking if an element exists. You can also apply URL pattern matching specifically for each extraction rule, to ensure computer resources are not wasted unnecessarily.
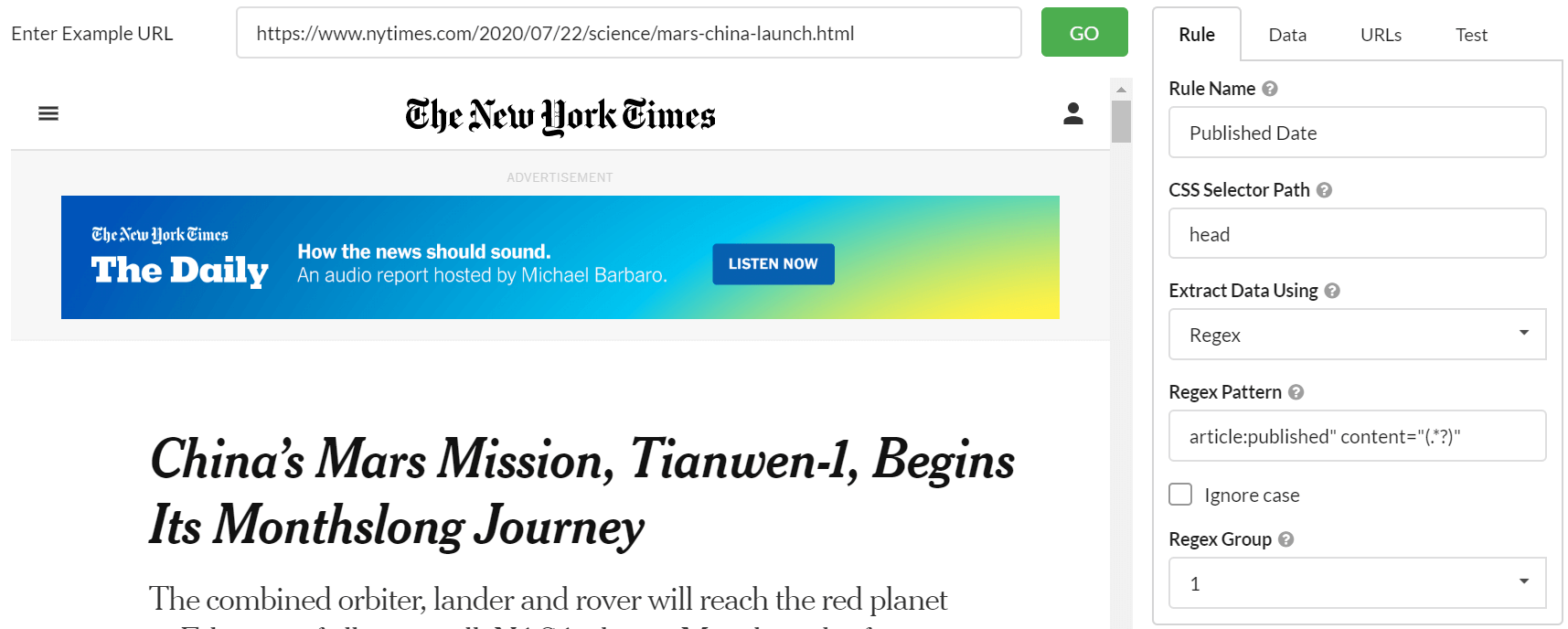
Scraping data with regex is typically an advanced use-case, and Sitebulb includes advanced functions to suit. You can specify a CSS selector in which to perform the regex pattern matching - rather than simply across the entire HTML document - and additionally pull from specific regex groups.
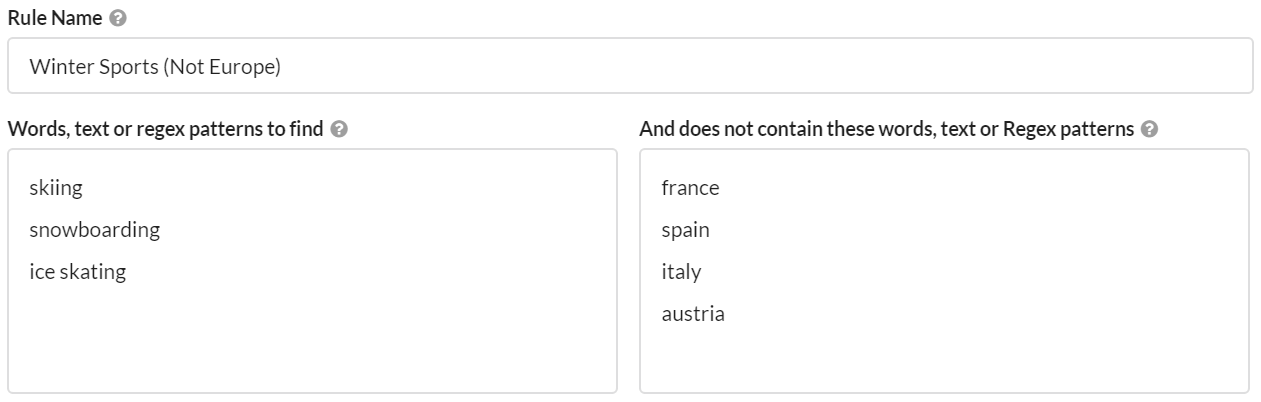
Flexible content search
Content search is a simple concept; provide a word or phrase for the crawler to check for in the HTML of every page. The setup in Sitebulb does not overcomplicate this basic process:
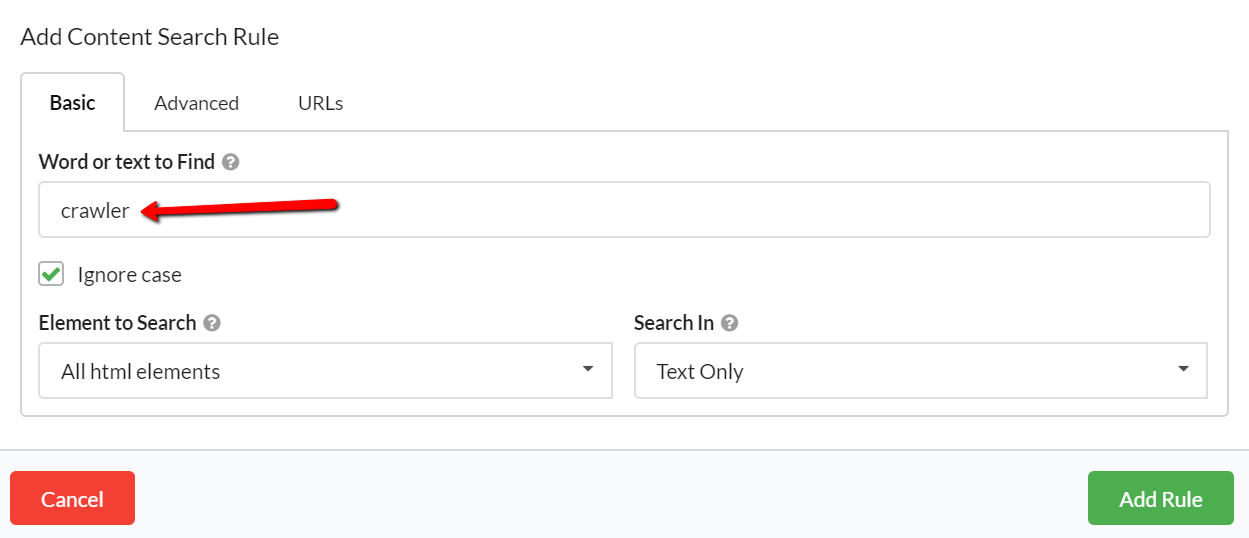
As always, however, Sitebulb offers that little bit more for those that want it, allowing you to combine words and phrases and even set exclusion patterns.