The aim of this post is to provide a methodology for crawling large websites with Sitebulb.
Crawling large websites is a tricky subject, primarily because of the number of unknowns. Until you actually crawl a website, you don't know if you're working with a 1,000 page website or a 100,000 page website. And that is before you start thinking about embedded resources, external links and subdomains.
But when you are dealing with a big website, crawl data can be incredibly valuable, as it can reveal patterns and issues that you'd struggle to detect otherwise.
So that leads us on to an important question:
This can depend on perspective. An experienced enterprise SEO who is familiar with 1 million+ page websites might see a 5000 page site as tiny. But to a solo in-house SEO in their first job, it can feel enormous.
For the sake of argument, we'll draw the line at 100,000 URLs. This is the point at which you might need to start thinking about which crawl and analysis options you have switched on in Sitebulb.
In general, for sites smaller than 100,000 URLs, you should be pretty safe turning on whichever crawl options you like.
We'll work through an example, say I needed to crawl the Patient website, which is a UK based health advice site, for doctors and patients alike.
If I were actually working with the client, one of my initial Q & A questions would be to ask them about scale, but since I'm not, we'll lean on our friend Google.
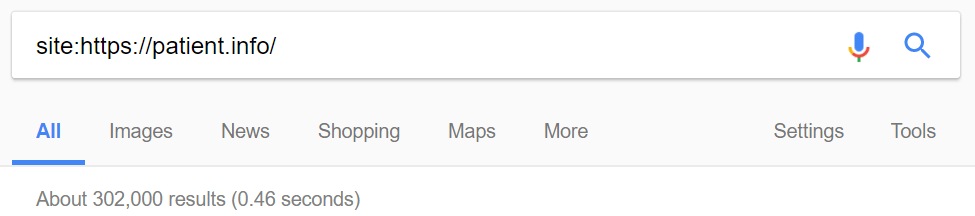
First things first, this does NOT mean that we will need to crawl exactly 302,000 pages. Not included in this total are noindexed URLs, disallowed URLs, canonicalized URLs, page resource URLs, external links or links to subdomains - yet all of this stuff could end up in the scope of your Audit if you are not careful.
If anything, what Google displays can only really be considered a lower bound, for the purposes of planning a crawl.
At this point we know it's a pretty big site, so our first port of call is a Sample Audit.
The point of a Sample Audit is to crawl a small subset of a website, in order to get a feel for how a full Audit will go.
We first need to set up a new Project in Sitebulb.

Once we hit 'Save and Continue', Sitebulb will go off and perform a number of 'pre-audit checks', such as checking the robots.txt file to make sure we can actually crawl the website in the first place.
Once the pre-audit is complete, we need to select 'Sample Audit' from the dropdown:

You will notice that the sample crawl settings will now appear, which is how we will limit the crawl. In this case, we are only going to crawl 10 levels deep, and a maximum of only 1500 URLs at each level (Sitebulb will choose 1500 random URLs to crawl at each level). The maximum URLs to Audit should stop the crawler at around 10,000 URLs.
The default option is to use the HTML Crawler, and to collect Page Resources, so we will not change any of this, then set the audit running.

If you keep an eye on the speed, this will give you an idea how fast the site can be crawled, and therefore how long it might take to complete the main audit. In this case we're at around 8 URLs/second, which is relatively fast. You can also experiment with ratcheting the speed up and seeing how fast it will comfortably go (watch out for errors creeping in, this typically means you are going too fast).
Once the Sample Audit has finished running, we can use the data collected to make inferences about how a full Audit would work on the site.

One thing we can clearly see is that there is roughly one page resource URL crawled, for every internal URL crawled.
This means that if we included Page Resources in our main Audit we would roughly double the amount of URLs we need to crawl, so 300,000 suddenly turns into 600,000.
There was also roughly one external URL crawled for every internal one, so across 300,000 internal pages this would add another 300,000 external URLs.
The point in doing this is to help us build up a profile of the website crawl to answer the question: 'what would it look like to do a full crawl of everything on the site?'
Then we will get an idea of how long it will take, to help decide if we are willing to wait this long for all the data.
Another element worth considering is how many indexable pages our sample crawl turned up, which we can get from the Indexability report:

The data in this report is potentially game changing - this is because all our assumptions are based off how many URLs are currently indexable. So, for example, if you came across 2 'Not Indexable' pages for every one that is indexable, your crawl would likely be three times bigger than expected.
In this case, it's not such a massive problem, but we still have one Not Indexable page for every 10 Indexable.
We can now build up our profile of what a full Audit might look like:
So if we wanted to crawl everything, we'd be looking at crawling around 930,000 URLs. At a rate of 8 URLs/second, this would take about 32 hours to complete.
Bear in mind that this is all based on using the HTML Crawler. If you want to use the Chrome Crawler, it will take a LOT longer, and you would need to repeat the above exercise using your Chrome results to reach a useful conclusion.
At this point we have a fairly good estimate for how long a full Audit would take, with the HTML Crawler.
If we wanted to move forward and carry out the full Audit, we could ask ourselves if we really want to wait this long, or if we'd be comfortable omitting some of the data.
There's no way to not crawl 'Not Indexable URLs' (because Sitebulb only knows they're not indexable once it has crawled them...), but we can exclude external URLs and page resources, which would keep the total down closer to the 300,000 we started with.
To do this, we'd start a new Project and this time select 'Standard Audit' from the dropdown instead of 'Sample Audit.'
In fact, these are not crawled by default, but it is easy to switch them on by accident.
If you don't want to crawl page resources, you need to leave both of these options unticked:

The 'Page Speed, Mobile Friendly and Front-end' checks all require Page Resource data, so you can't have any of these options ticked.
Of course, if you really want access to these reports, then you'll have to bite the bullet and switch them on, just bear in mind how it will affect the Audit size and speed.
To find this setting you are going to have to scroll all the way to the bottom of the setup page, and hit the 'Advanced Settings' button.

Then on the 'Configuration' tab, untick the two boxes 'Check subdomain URLs' and 'Check External URLs' (which are both on by default).
This is the best way you can limit the size of the Audit, without deliberately excluding internal pages in the site.
Finally, you can also exclude internal URL paths and/or parameterized URLs through the Advanced Settings. We've written a separate guide which covers that topic, as it can be quite involved: Limiting the Crawler for Faster and Cleaner Audits.
This final note is nothing to do with how you arrange the crawl setup, but more to do with how to manage your computer. Ideally, you want to leave Sitebulb to run continuously, complete the crawl and generate all the reports.
However, with bigger Audits it may not be possible to leave your computer on for a long period (e.g. overnight), so the best option is to utilise the 'Pause' feature.
While an Audit is in progress, just hit the purple Pause button in the top right.
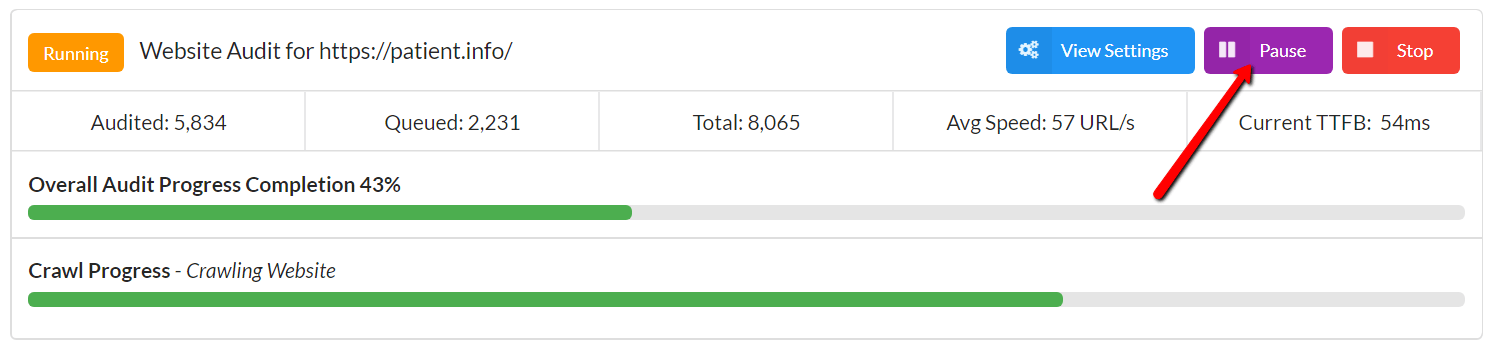
Once you've done this, wait around 5 seconds for the purple button at the top left to change from 'Pausing' to 'Paused.'
At this point you'll notice that there is now an option to 'Resume' in the top right.
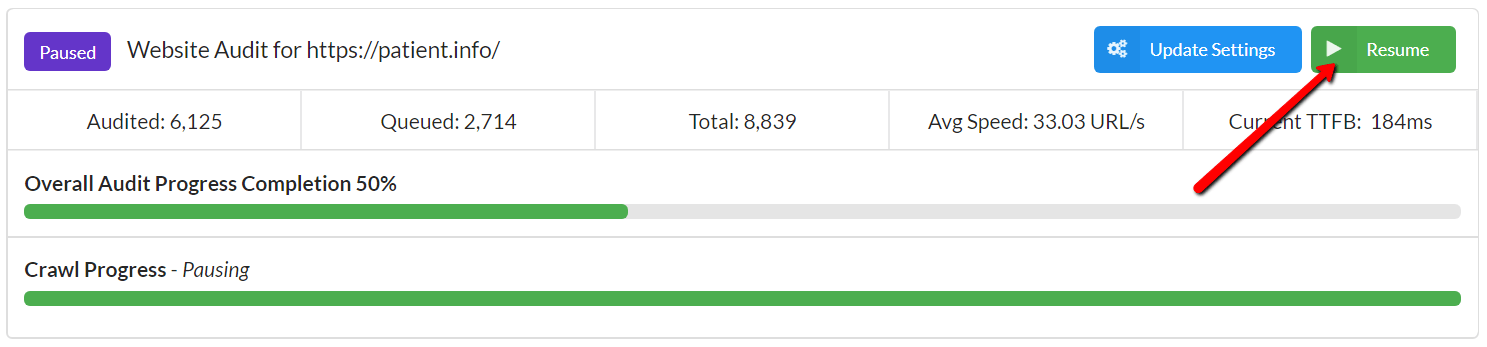
Once an Audit has been paused, you can close Sitebulb down and shut your machine down. Then when you reopen Sitebulb the next day, you'll see a message informing you that you have an incomplete audit, so you can jump back into it and get it going again.
To see a list of paused audits, click to view the Paused tab:
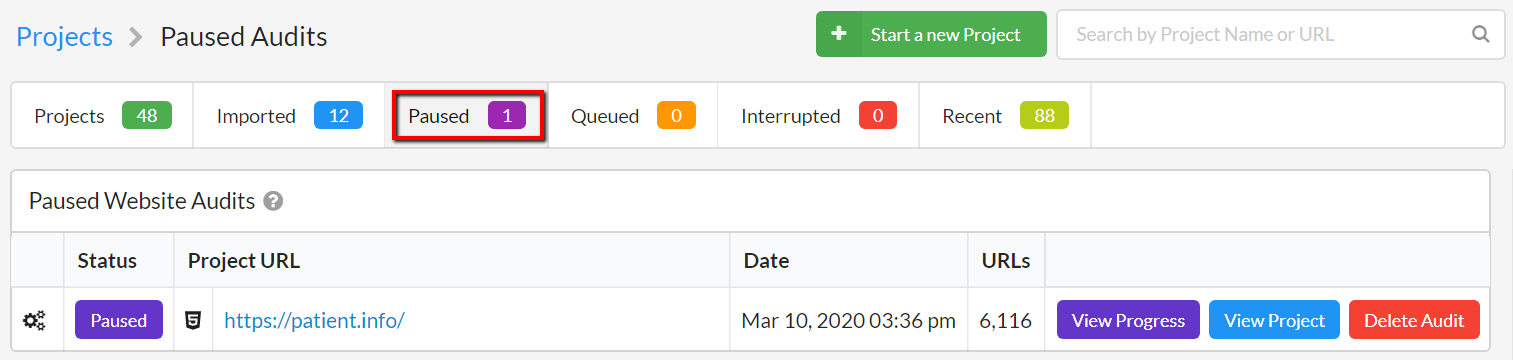
Hit 'View Progress' to return to the progress screen, where you can then hit 'Resume' to set the Audit running again.
If pausing is not an option, and/or you want to crawl a large site continuously for several days, the best option might be to leave Sitebulb to work uninterrupted on a VPS or cloud instance. If you want instructions on how to do this with AWS, please read our guide.
A final consideration when crawling large websites is to many sure you have enough space on your hard drive for the audit. One of the reasons Sitebulb can crawl so many pages is because it writes the data to disk instead of holding it in RAM.
A site with 100,000+ URLs could take up anything from 250 MB to around 2 GB. There's no easy way to know how much space you'll need before you start the Audit, but bear in mind that the more data you collect, the more disk space will be required.
In particular, 'Link Analysis' can take up a lot of disk space, as the numbers can grow huge very quickly.
To put this into perspective, I crawled a site recently with 1.6 million internal URLs. I crawled it once with 'Link Analysis' switched off, and this took up 6 GB of space on my hard drive. I crawled it again and switched on 'Link Analysis', and it was 36 GB!
Why so large? It had 142,600,000 links! That's why.