This guide gives a step-by-step walkthrough on how to search a website for a word, phrase, or string of text, and find every page which it appears on.
Sitebulb has a feature called 'Content Search', which allows you to configure the crawler to search a website for a specific word or phrase on every page that it crawls.
This allows you to then filter pages based on whether or not they contain certain words.
For example:
This guide covers the entire process for setting up content search within Sitebulb, including all the advanced settings.
You can jump to a specific area of the guide using the jumplinks below:
To get started, simply start a new audit, and from the setup options, scroll down to Extraction, and click to open up the Content Search option.

Then click the button at the top to toggle Content Search on and then on the green Add Rule button.
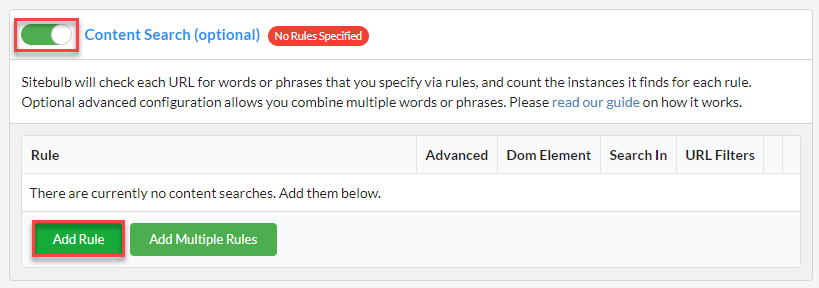
This will open up the on-screen rule wizard. For a basic search, all you need to do is enter the text and hit 'Add Rule', and that's all there is to it. You're now all set to search your website for this word, whatever it may be.
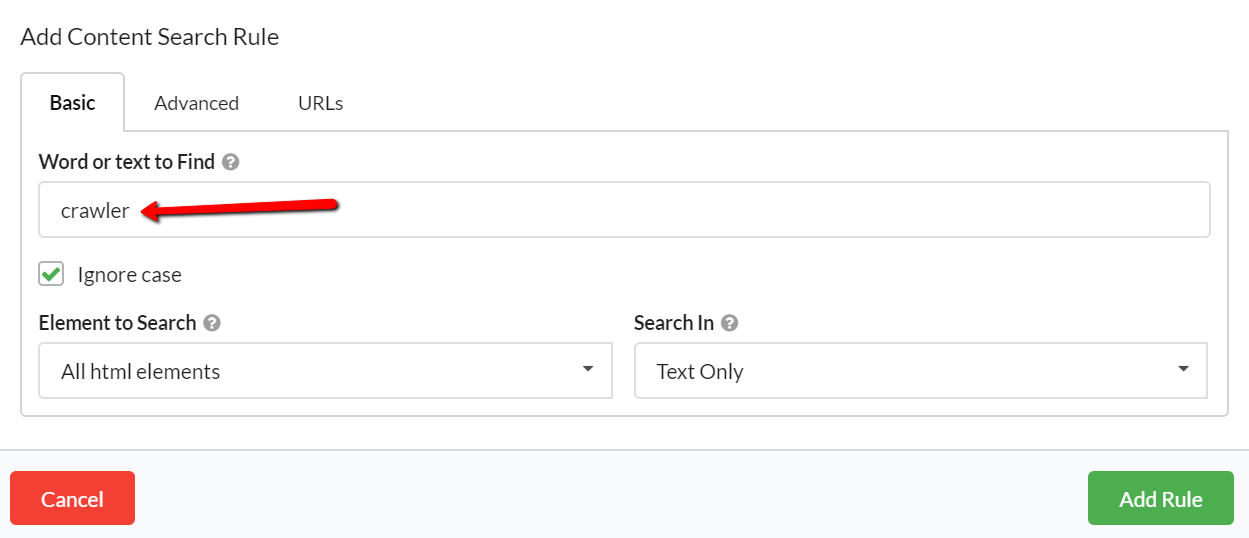
Once you've added your rule, you can stop there, or just keep adding more rules. You will see all your rules in the audit setup page, ready for you to start the audit.
For example, if we wanted to crawl our site and understand how often we reference Sitebulb as a 'crawler' vs a 'website auditor', we could set it up like this:

With a Sitebulb Pro license, there is no limit to the number of rules you can add, so collect all the data you need (with a Lite license there is a limit of 3 rules).
Once you're done adding rules and any other audit setup configurations, hit Start Now at the bottom right of the screen, to start the audit.
Once your audit is complete, you can access the data report using the left hand menu.
The Overview will show you details of the data totals for each different search phrase:
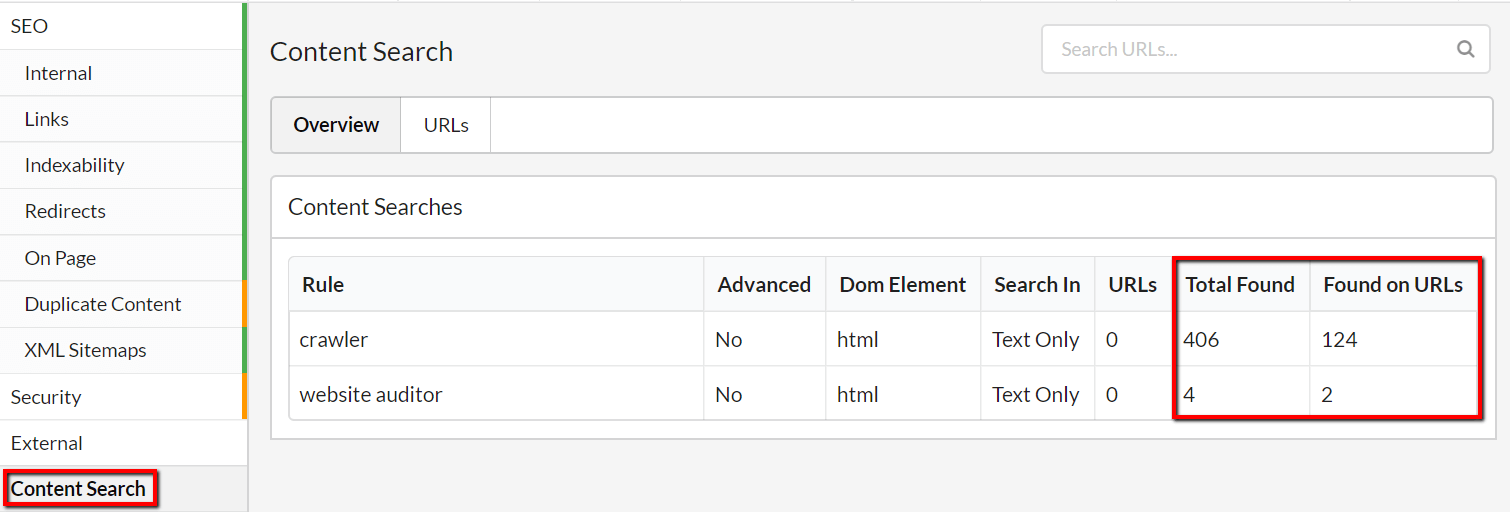
The two data columns tell you slightly different things:
Without even analysing the data in detail we can already see that 'crawler' is dominant.
To see the detail of specific URLs, we need to switch to the URLs tab, which shows the URLs alongside columns headed by the text/phrase filters. The numbers in each cell relate to how many instances of the phrase were found on each page.
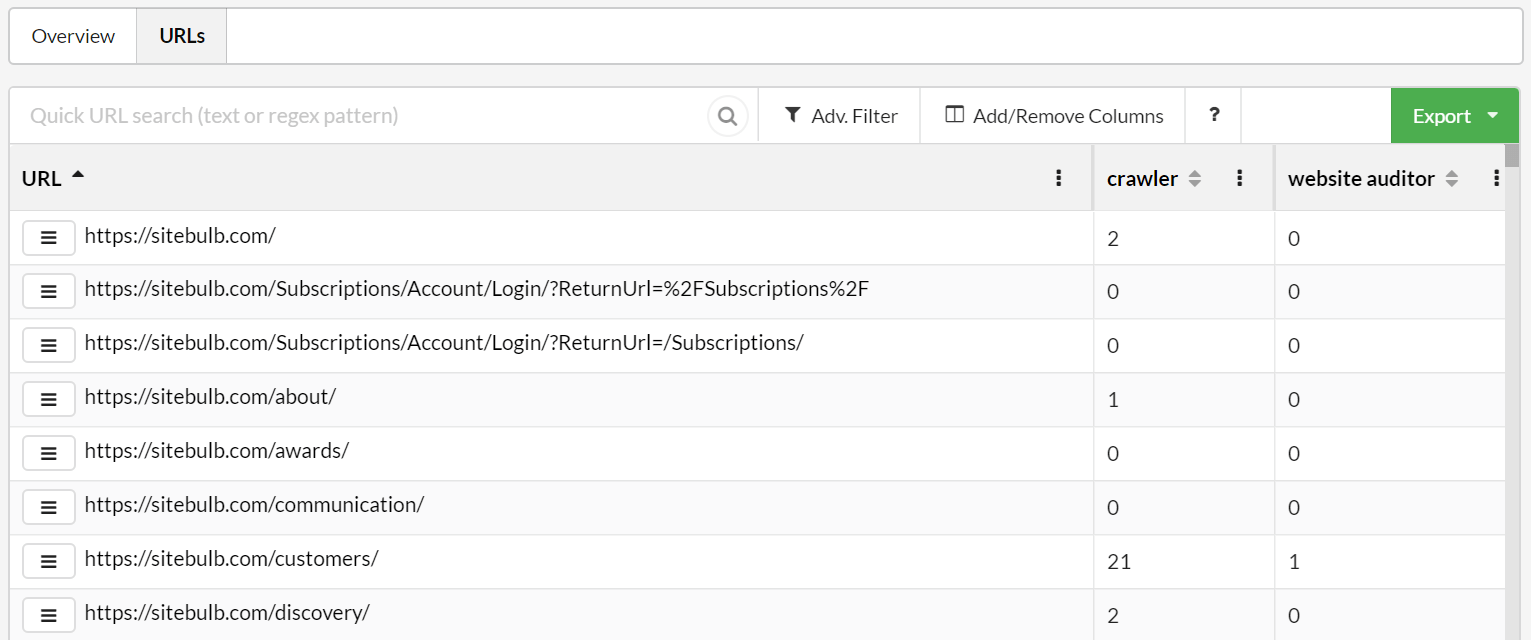
We can quickly sort this data by clicking the column heading for any search phrase we want to sort by.
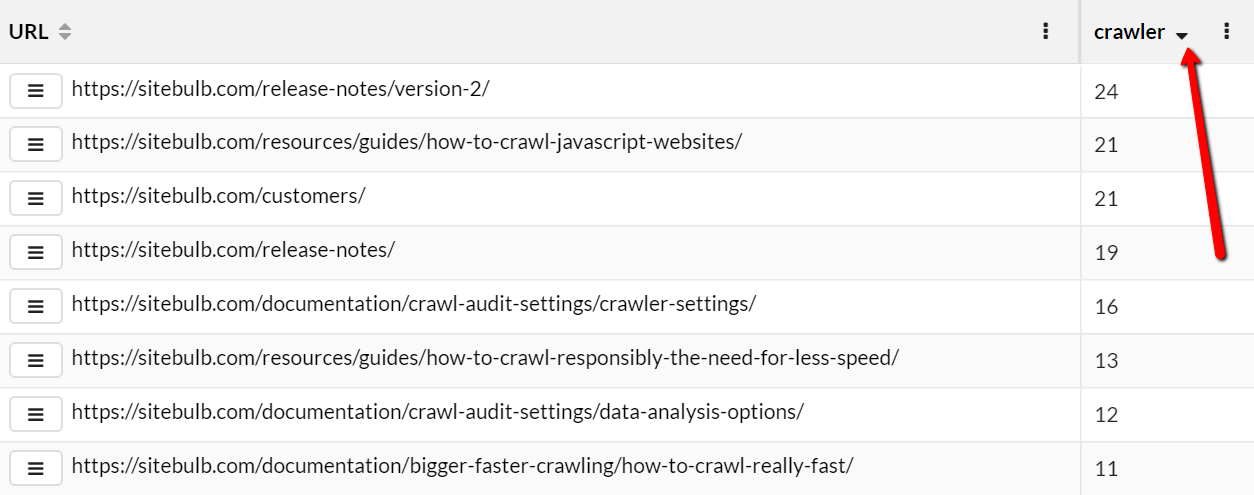
As always with URL Lists, you can add or remove columns so that you can easily combine technical crawl data with your extracted data. You can also create filters on the data to gain additional insights.

That is the basic setup, and this simple process will allow you to easily set up content searches and view the data in your results.
The process outlined above is suitable for most simple use-cases of content search. However, there are some additional settings we have yet to explore.
The image below shows the default setup, with an example search phrase:
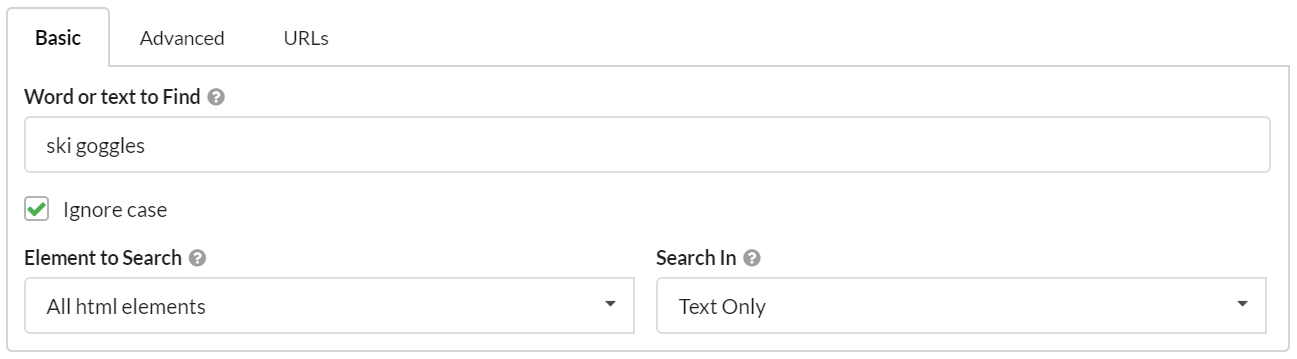
Let's dig into what each option means in more detail:
Most of these options are quite intuitive and/or straightforward to test and verify yourself. However, the option 'Element to Search' is a bit more nuanced, and requires a bit more explanation.
For a start, there are a number of options on the dropdown:
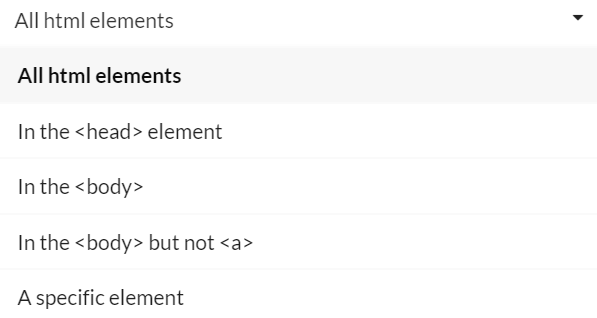
What all these options refer to is the HTML structure of the webpage:
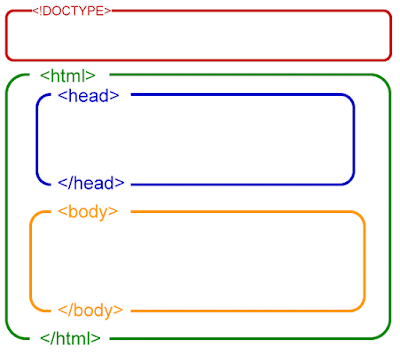
So, the default option 'All html options' will search the entire green section from the image above. You can select to only search in the <head> or the <body> (blue or yellow sections) or alternatively, 'In the <body> but not <a>'.
This specific option means that Sitebulb would search in the <body> (yellow) section only, but it would not include any anchor (<a>) elements. In other words, search the body content but don't include any links.
For example, let's say we wanted to point some more internal links at our JavaScript crawling page. If we search for the phrase 'javascript crawling' in the entire <html> or entire <body>, this will catch all the links in our top navigation panel:

So literally every single page would get flagged. Not helpful at all.
But if we instead choose '<body> but not <a>' then this would only pick up the instances where the phrase is present in the non-link <body> elements.
Very helpful indeed.
And finally we have the bottom option from the dropdown: 'A specific element'. When you select this, a new box appears underneath, which requires you to enter the CSS selector which defines the specific element you wish to scrape. For example:
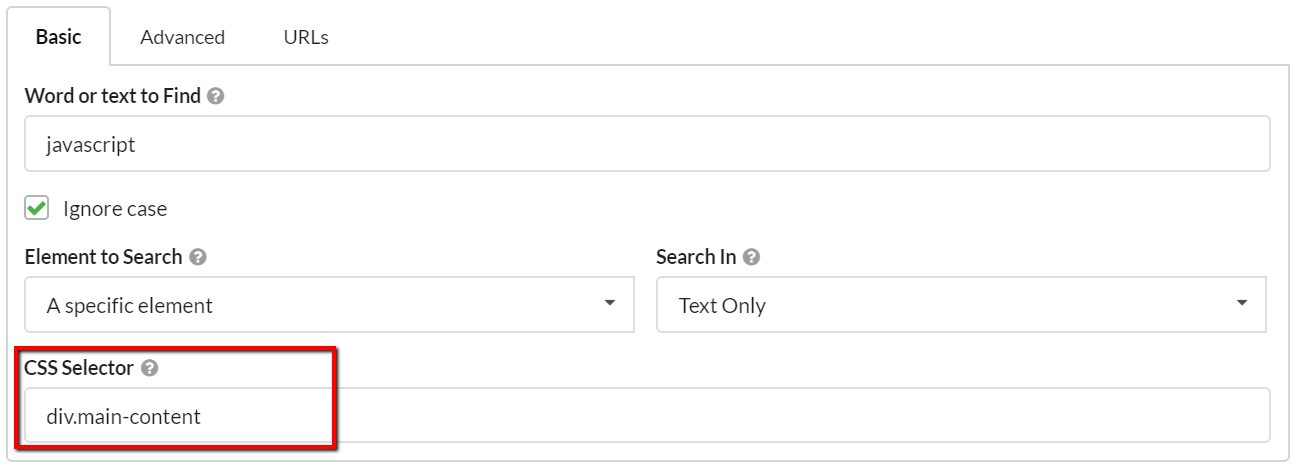
In general, this should be considered an advanced option - if you have no idea what a CSS selector is then just avoid this option and stick with the others, they are more than adequate for almost all use-cases.
The CSS Selector allows you to pick out a specific section from a page template. Consider a typical ecommerce product page, I may only be interested in searching the 'content text' portion of the page - not the navigation elements or boilerplate copy.
So I need to pick out the selector which defines this, which I can do using the 'Inspect' feature in Chrome:

So in this instance I can see that the inspector I need is: div.product-description-content-text
By highlighting this selector in DevTools and scrolling the page down, I can see that it neatly dissects the page to only pick out the product description, and avoids the boilerplate fluff like 'The small print', which I am not interested in searching.

For clarity, here is how I would set up the rule in Sitebulb:

If you have LOTS of words/phrases you wish to search for, utilise the 'Add Multiple Rules' button in order to add them in bulk.

Simply write your words/phrases, one per line, or just copy/paste into the box. It works exactly like the single 'Basic' configuration above, except for multiple words or phrases. So you can still configure the URL exclusion patterns, which element to search, and whether you search in the text and HTML or just the text.
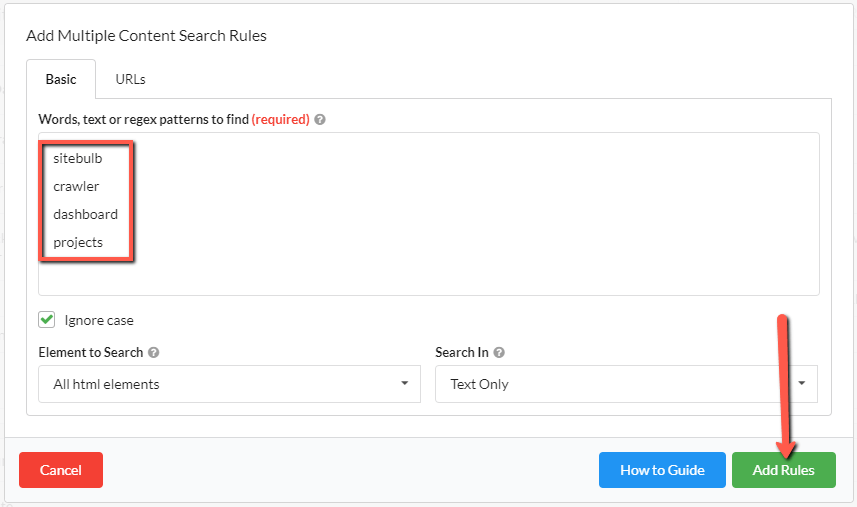
So this does not give you the granularity to configure each word differently, but does allow you to bulk upload hundreds or thousands of phrases all at once. This can be really useful if you're looking to identify pages which contain any one of a list of keywords.
When the report is complete, each rule will display as if you had entered them one by one:

With this feature it is possible to dump thousands of words in at once. Note that if you do this, the best way to access the data is to use the green Export All Search Data button you see in the image above. You CAN access the data via the URLs tab, but it will only load 50 columns in at a time, so you would need to do a lot of add/removing to see what you want.
So our recommendation is to use the export instead.
Everything we have covered so far falls under the umbrella 'Basic' setup. This essentially means we are asking Sitebulb to search for one word or phrase at at time (even via the 'bulk upload' method).
But there is also an 'Advanced' option, on the single 'Add Rule' window.
Here's the deal - you either set up each rule as 'Basic' or you set it up as 'Advanced'. It's not a situation where you set up the basic stuff, and then go and add some advanced options. As such, there are some familiar elements that work exactly the same as described above for the Basic options. And then there is some new stuff:
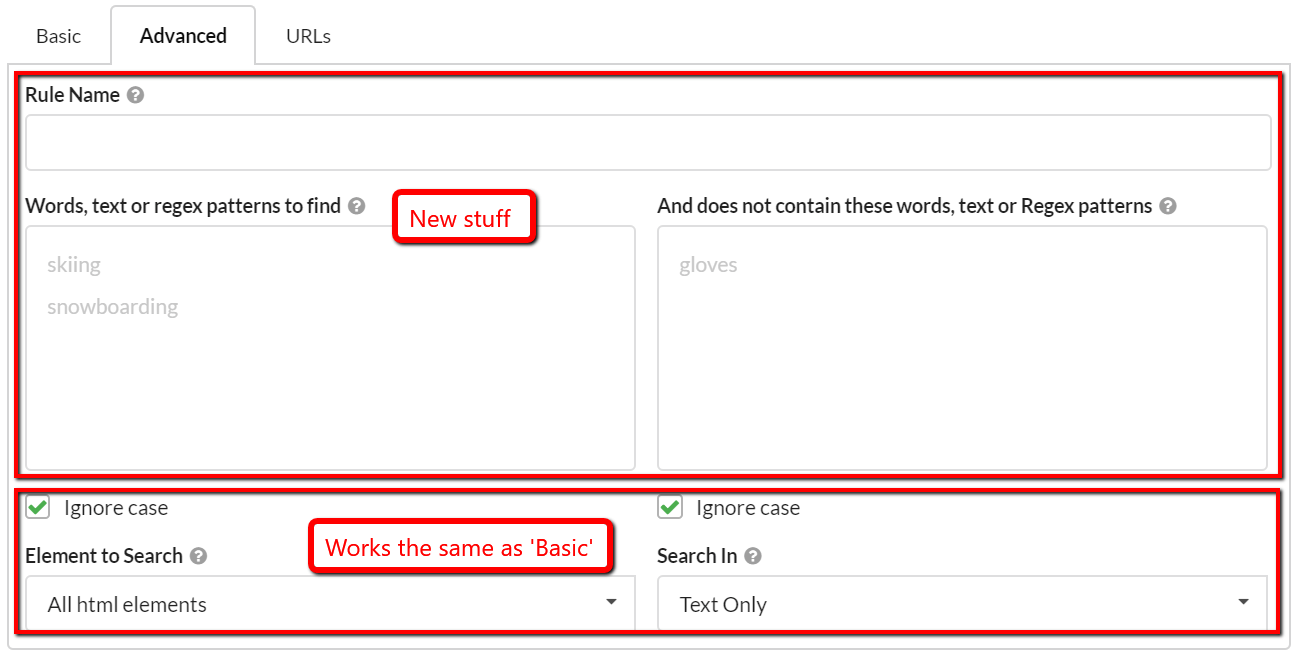
So, we won't cover old ground with the bottom bits again, please just refer to the section above which explains how that all works.
We are interested in this bit:

The concept is relatively straightforward, we are replacing 'word/phrase' with a combination of words to search for. The requirement to provide a 'Rule Name' is simply to make it easier to view the results in the report.
Let's work through an example. Imagine we are auditing a travel website. We want to identify pages that talk about specific winter sports, so we could set it up like this:

Once this rule is applied, Sitebulb would search for any pages that contain either 'skiing', 'snowboarding' or 'ice skating' (or any combination of the three).
When we take a look at the results, you can see the value in adding a rule name:
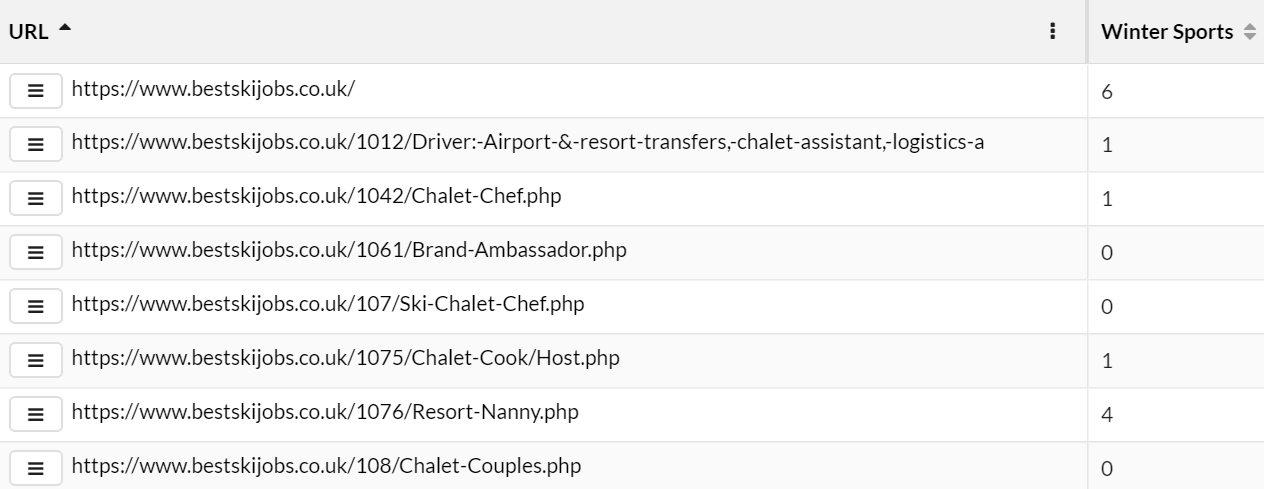
In this case, the numbers returned in the 'Winter Sports' column reflect the total number of matches. So a result of '6' might mean that 'skiing' is mentioned 4 times, 'snowboarding' 2 times and 'ice skating' not at all.
Now, imagine we wanted to identify pages that talk about specific winter sports, but only for certain countries. We could rule out specific countries by adding them in the right hand 'does not contain' box, e.g.
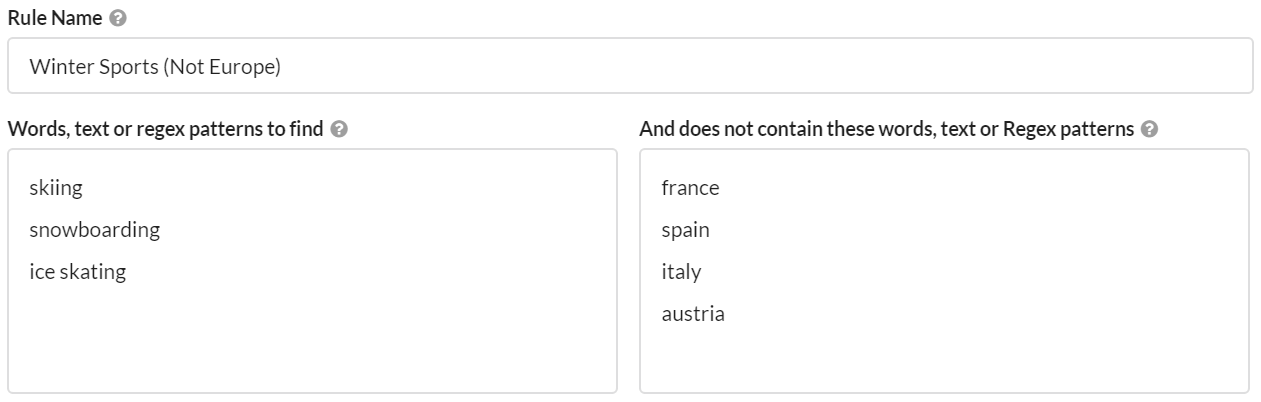
Once this rule is applied, Sitebulb would search for any pages that contain either 'skiing', 'snowboarding' or 'ice skating' (or any combination of the three) AND ALSO contain none of 'france', 'spain', 'italy' and 'austria.'
What this does is surface the pages about USA/Canada instead of Europe, as we wanted:

Using this combination approach allows you to do things like categorise pages based on topic, or group them based on a set of target keywords - which could then be used for content audits or internal linking strategies.
By default, Sitebulb will perform the content search on every single page on the website. This means you are asking Sitebulb to do more work in terms of processing, and it means more data will be stored on your hard drive once the audit data has been collected.
For most websites - for instance, a typical 10,000 page site - there is no issue with this, as the size and scale of the additional resource requirements is negligible.
However, Sitebulb can handle websites with millions of pages, and at this sort of scale you might want to look at reducing the amount of processing work Sitebulb has do while crawling, and perhaps more pertinently - how much space the audit will take up on your hard drive when it is done.
This is what the URLs tab is for. You can enter inclusion or exclusion patterns so that Sitebulb will only perform the content search analysis on specific pages.
Returning to an example on this website, let's assume we wanted to find pages that mention 'crawler', but we don't want to perform the search on any of our /documentation/ pages (such as this very URL), we would enter the /documentation/ path with a minus (-) sign ahead of it:

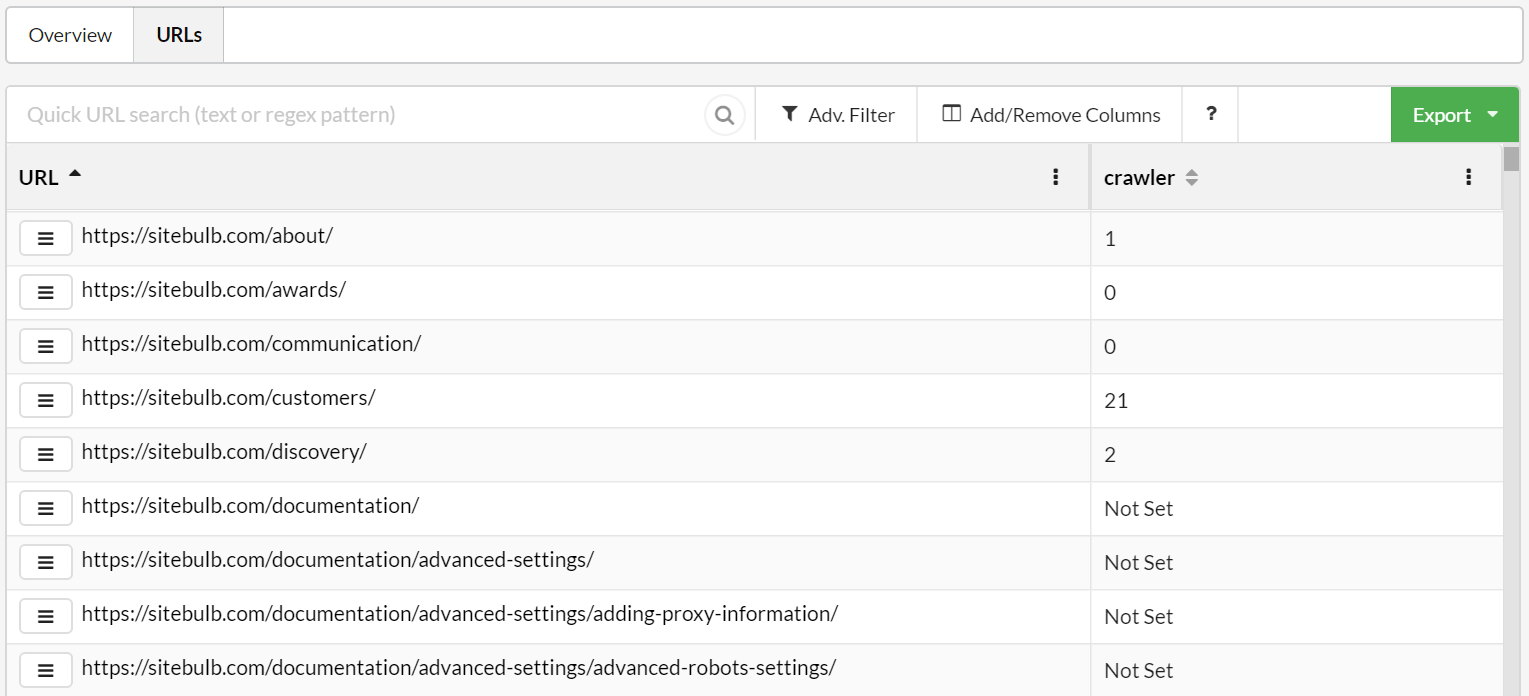
In the results, the /documentation/ pages are simply listed as 'Not Set', so you can differentiate the legitimate zeroes from pages where Sitebulb simply did not perform the search.
We could also do this a different way, by using inclusion patterns instead. Perhaps we only wanted to check for the word on our 'sales' pages on the site, we could select to only perform the search on /product/ and /features/ pages, by entering the folders WITHOUT a minus sign:

The results for this one show how we are able to isolate the pages we are actually interested in, and easily differentiate the 'true zeroes':

The URL matching works for either the Basic or Advanced rules, and can be defined differently for every rule you add - so you can get super specific in your setup.
In addition to the examples already covered in this post, we also have a tutorial video with some different examples, which showcases some of the different features and options within content search:
The final thing to point out is that on some sites, content is loaded in via JavaScript, which means it is not possible to view this content when you do 'View Source.'
If you want to better understand why this happens, have a look at our guide on crawling Javascript websites. But for now, if this is the case on the website you are crawling, you just need to switch to the Chrome Crawler in your audit settings, and this will ensure that you can search your site as Google sees it.
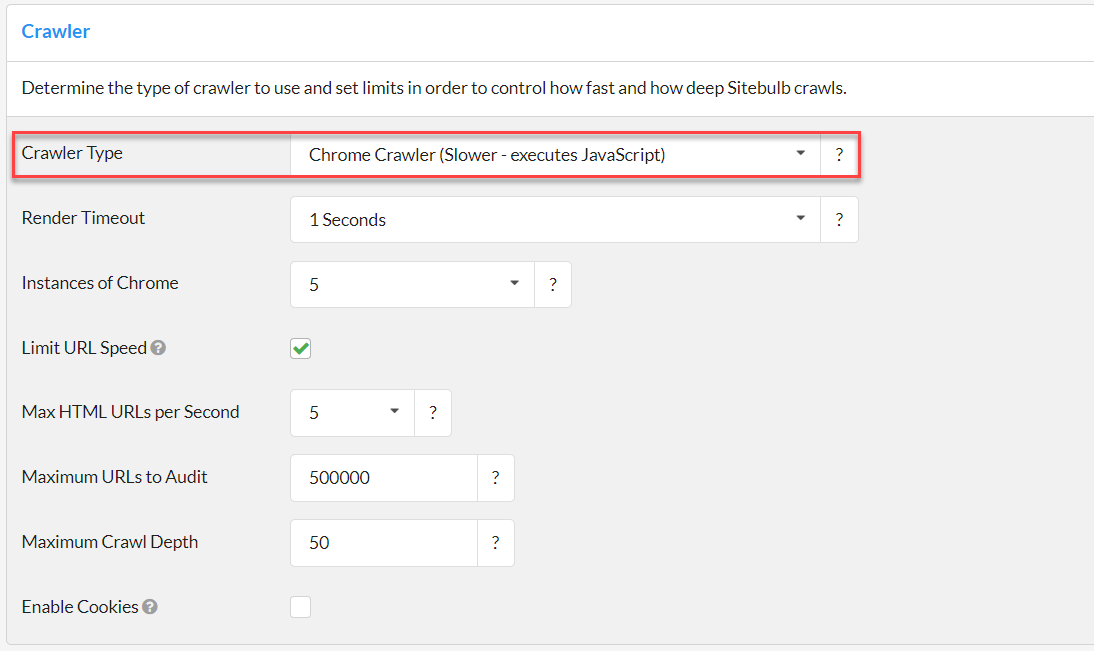
This means that Sitebulb will render the JavaScript before performing the content search.
Don't worry! You can register for a free Sitebulb trial here and get started straight away.