Sitebulb Version 4
Version 4 was developed while we were all locked inside drinking too much and apparently homeschooling. We released it during the heart of the pandemic in August 2020, and the big thing we added was structured data validation.
Version 3 was developed mostly during 2019 following on from Version 1, Version 2 and the beta years.
Version 4.7.2
Released on 13th April 2021
While most of you have been enjoying the blissful freedom of another day without yet another Sitebulb update, we have been feverishly working to get version 5 (codename 'v5') completed. However, we felt like it was high time we bestow some improvements upon on our loyal followers, since it is a Tuesday and everything.
Updates
Updated structured data validation
Since our last dance, there has been a veritable gamut of changes and updates to Google's Search Feature support, along with a new Schema.org release.
Most notably, this included the two newest rich results: Math solvers and Practice problems. We've updated the Sitebulb validation to include all the latest changes, both in the crawler and also in the standalone structured data testing tool:

By the way, if you're sat there thinking, 'WHO WHERE WHAT WHEN ON EARTH DID THIS NEW STRUCTURED DATA APPEAR AND WHY DID NO ONE THINK TO TELL ME ABOUT IT?!?!?'
Well, you might want to sign up for our handy (and free) Structured Data Update Alerts, so that future-you is not so easily blindsided.
URL Details will now export to Google Sheets
From the single URL Details view, you can now export the data not just to CSV, but also to Google Sheets:

Bugs
Fixed some of Gareth's typos
Every so often, I get to watch Gareth code. I by 'get to', I mean I am forced to. As both a non-coder and a vocal dissenter against the 'SEOs must learn to code' brigade, I am consistently impressed by the attention to detail required of Gareth to make sure the code works exactly as it should. It is quite remarkable.
What is more astounding, however, is that whenever he required to write basic simple English sentences for the UI, they will contain, without fail, a series of embarrassing typos, the level of which my 6 year old boy would be ashamed of.
Trying to reconcile these two truths makes my head hurt.
Resolved 'missing h1s' on International audits
One of 2021's more riveting narratives, 'The Great H1 Heist' was finally put to bed. After a deep dive investigation in conjunction with intelligence services across the globe, a fatal flaw was discovered in Sitebulb's hreflang algorithm, causing H1s and other such related data to mysteriously disappear on external URLs found via hreflang.
The missing data has been restored, and multiple as-yet-unnamed suspects will now face trial by combat.
Fixed inconsistent data for null values
We had a bunch of data columns which included these values:
- Yes
- No
- False
Which is a bit shit, really. Users were complaining that this was causing havoc when importing into R/Python, which is what all the cool kids love to do these days. This was due to the 'null value' not being explicitly set.
To fix this, we've updated the default value handling for boolean (true/false) values. If a boolean defaults to false then we'll now display "No" in the same way as we would if the column was explicitly set to false.
Code coverage bug fixed for Arnout
Long time Sitebulb fan and famed oyster lover, Arnout Hellemans, is known in these here parts as 'literally the only person who actually uses Code Coverage'.
Every so often he will take a break from his Weber grill to let us know that something is not working quite right on the Code Coverage report. Normally it is an obscure implementation that affects 1 website in a million, which he unerringly seems to unearth every time he works with a new client. On this occasion it was regarding stylesheet links in the <body> rather than the <head> (which is 'bad practice' apparently, but who's counting?).
We try our best to slowly back into a bush and out of sight, but always cave and end up fixing the issue.
Night mode UI error
I have a confession to make. Despite regularly extolling the virtues of James Bond mode, I literally never use it. So it takes self-proclaimed 'not even an SEO' Russ McAthy to point out these sort of embarrassing blunders...

I mean, look at the fucking state of that.
Fixed issue with inaccurate subdomain categorisation
We hadn't planned this final bug fix, but I insisted we shoehorn it in, after throwing an egg directly at my own face. Friend of the show Kristine Schachinger asked an innocent question on Twitter, absent-mindedly tagging our frog-shaped friends instead of us.
I spotted it and hastened a hilarious response, much to my own amusement:
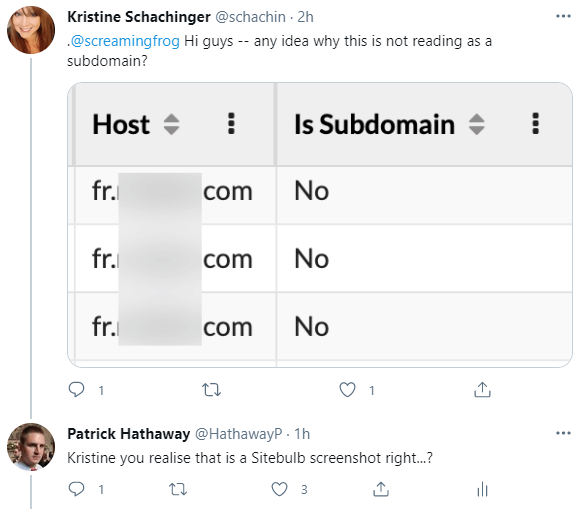
Once I'd finished bathing in my own snark, I figured it was only right to help Kristine figure out what she was doing wrong...
Alas, it transpired it was I who was wrong, and Sitebulb that was broken!
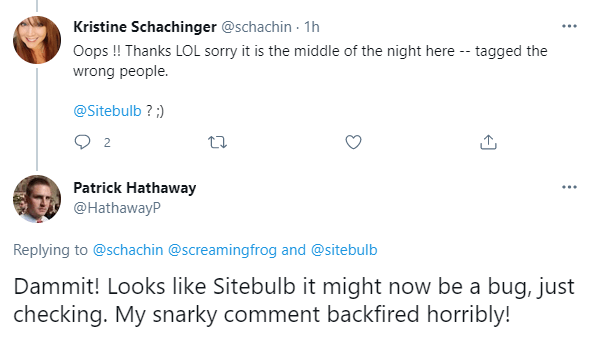
The lesson is, never try.
Version 4.7.1
Released on 18th February 2021 (hotfix)
Bugs
- We had an issue with the render timeout not being correctly set (when using the Chrome Crawler), which was causing Sitebulb to crawl certain sites incorrectly.
- We recently updated Sitebulb to correctly recognise Chinese language tags zh-hans and zh-hant in hreflang. Our fix inadvertently meant that ALL OTHER hreflang pairs (e.g. en-gb) became classed as invalid. I suggested that we just tell all our users to switch all their content to Chinese, but this was over-ruled, in favour of just fixing the bug.
- Content extraction - if you added an attribute (e.g. 'href') this was not being saved properly. While fixing this, we discovered that we'd spelled the word 'attribue' in a few places (a more heinous crime imo), so we fixed this too.
- Sitebulb's crawl limit for Pro licenses should allow users to set up to a maximum of 2 million URLs, with 500,000 set as the default. However the default had started acting like the upper limit, so users could not set it over 500,000.
- Google Sheets upload was not working if you had an apostrophe in the project name. Because apostrophes are devil spawn, and arguably more dangerous to mankind than the Millennium Bug.
Version 4.7
Released on 4th February 2021
One of the main reasons for today's update is because we've been getting reports of users literally unable to run any audits. Upon investigation, we found this was because they had set their 'Project Data' to save to a cloud folder (Dropbox, iCloud, Google Drive, etc), and were experiencing issues because the cloud folder would lock the files and make it impossible for Sitebulb to write data.
This was our fault, as we suggested this as a viable option. It had worked fine during testing, but in practical real world situations, it didn't work well at all. We live and learn, and have now tried to make it clear that this is not a sensible option within the settings:
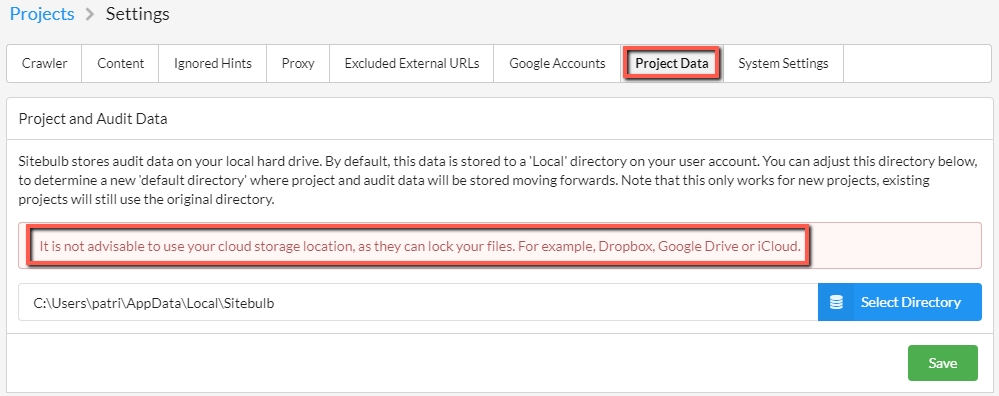
If you know you've set this folder up as Dropbox (or Google Drive, iCloud etc...) - whether or not you've experienced issues up to now - we advise you to urgently change it to a local drive. If not, you may experience data loss, or the issue I mentioned above where you are completely unable to run audits.
From speaking to the folks affected, it seems most users are doing this as a way of trying to 'sync' data between different machines. Sitebulb does not currently have a 'perfect' way to sync data between machines, but the easiest way to do it is via the Advanced Setting option: Save export data to a custom folder, which needs to be configured per Project.
Updates
#1 Improved handling of timeout URLs
The internet we know and love is, I'm sad to say, blighted by atrocious websites. Some websites are so badly put together that even highly responsible crawling at very slow speeds will cause the server to shit itself.
We recently encountered some websites whose pathetic reaction to being crawled was decidedly Trumpian, where the server would hang on to URL requests, obstinately refusing to move on.
Sitebulb also did not cover itself in glory when it encountered such pitiful websites, getting itself in something of a tailspin and struggling to deal with dozens of URLs all timing out at the same time.
We've improved the stability of this processing, so it can handle dogshit websites as well as decent ones. While working on this, Gareth added a 'Processing' status on the crawl progress, to help him diagnose where Sitebulb was getting stuck. He got used to it and started to kinda like it, so we've kept it in for you to enjoy too.
This will display as below, allowing you to see which URLs Sitebulb is working on, and will help you to see how easy (or hard) Sitebulb finds it to crawl the website.
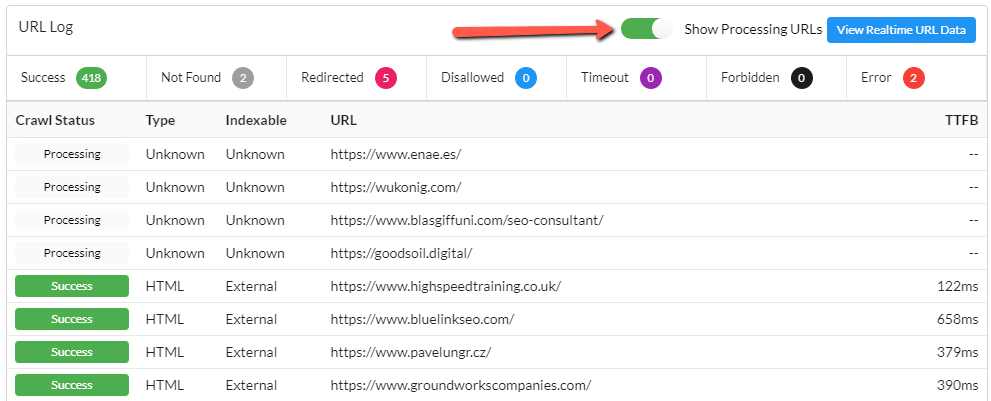
This will be on by default unless you set the maximum threads to be over 10, at which point it will be off by default (because basically all you ever get to see is 'Processing' and it looks shit). You can easily toggle it on using the button displayed above.
#2 New 'overwrite canonical' option for staging sites
My good friend Anthony Nelson requested this improvement ages ago, but I couldn't convince Gareth that it would get used. Roll forward to yesterday afternoon:
Gareth: I need to crawl this client site on a development server.
Patrick: Lucky you have literally built a crawling tool that solves exactly this problem.
Gareth: Fuck off. Problem is I can't check Indexability, as all the canonicals point to the live site.
Patrick: So everything shows as canonicalized, right?
Gareth: Yes. It's a pain in the arse. So what I want to do is add a staging site setting to rewrite the canonical.
Patrick: That is literally the exact same thing Anthony asked for years ago and you refused to build it.
Gareth: Well now I need it or I can't check this site!
Patrick: You're already building it aren't you.
Gareth: Yep. Tell Anthony thanks for the great idea.
So...erm... thanks?
To clarify, the only time you need this is if you're crawling a staging site that sets canonical URLs using the 'live' website hostname, rather than the dev site.
So for example, your dev site is https://devsite.example.com and you have URLs of the form https://devsite.example.com/page which set the canonical URL as https://example.com/page.
If you DON'T tick our fancy new box, Sitebulb will see these URLs as canonicalised to a completely different subdomain, and they will be reported a 'Not Indexable'. If you DO tick the fancy box, Sitebulb will store the canonical as https://devsite.example.com/page (in essence it just re-writes the hostname) and the Indexability reports will work as designed.
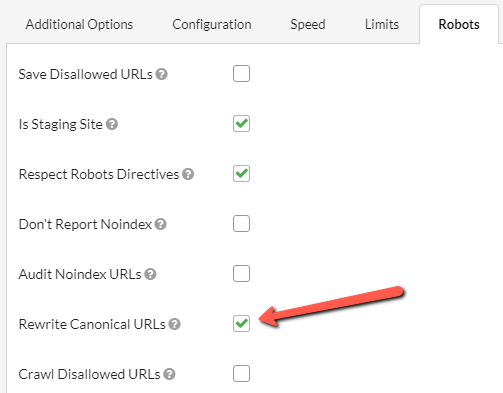
It's still a feature that will maybe be useful on < 0.005% of all audits, but when you need it, it works pretty sweet.
#3 Added new error message to structured data validation
Sometimes structured data will fail because Schema properties have been set using the incorrect case (e.g. 'accessmode' vs 'accessMode' in the example below). Previously Sitebulb would flag this as a generic error, but not explain why it is wrong.
Now it tells you why:

Some of you will be grabbing your pitchforks at this; 'BUT THE SDTT DOES NOT FLAG IT AS AN ERROR!'
Maybe so, but it's still wrong. Y'all are probably the same folks who try to use proper nouns in Scrabble. Go ahead and get gone.
Bugs
- The robots.txt parser was ignoring allowed filetypes. Naughty robot (not a robot).
- Fixed a bunch of crappy styling bugs in James Bond mode.
- Sitebulb was trying to claim that zh-Hand and zh-Hans were not valid hreflang. It's always making these sort of audacious claims, this is why I can never invite anyone round for dinner any more.
- Added X-Content-Encoding-Over-Network header check, as ESET strips away the Content-Encoding header, which meant Sitebulb would misreport gzip compression. Seriously, virus checkers are a fucking pain in the arse.
- Accessibility checks (which take a long time) were not being given enough time by Sitebulb to complete, which was causing some data loss.
Version 4.6.2
Released on 11th December 2020 (hotfix)
Predictably, as soon as we anointed v4.6 as 'the last update of 2020', we promptly found a bug that we needed to fix. And then we found 2 more. And then needed to add something else.
2020...just fuck off already.
Update (singular)
New Advanced Setting option: 'Audit Noindex URLs'
The other night, in lieu of going to a pub (since they're shut) or to someone's house (since we're not allowed), I joined a few of my 'dad friends' and did a Beer Walk (that's what I'm calling it anyway). We literally wandered around the streets, enjoying beer and conversation (yes, very much like teenagers)... until we ran out of beer and went home.
I got home to find that we'd released a Sitebulb update, according to Marshall Simmonds anyway...

This is something you need to know about Gareth. If you need help with something, he'll bend over backwards to help you with it. It's just what he's like, it's in his DNA. It's also the reason me and him ended up working together in the first place, but that's another story for another release note.
Marshall needed a very specific setting adding to Sitebulb for a site he needed to audit, and so we have a new option in Advanced Settings -> Robots: 'Audit Noindex URLs'
And it lives here:
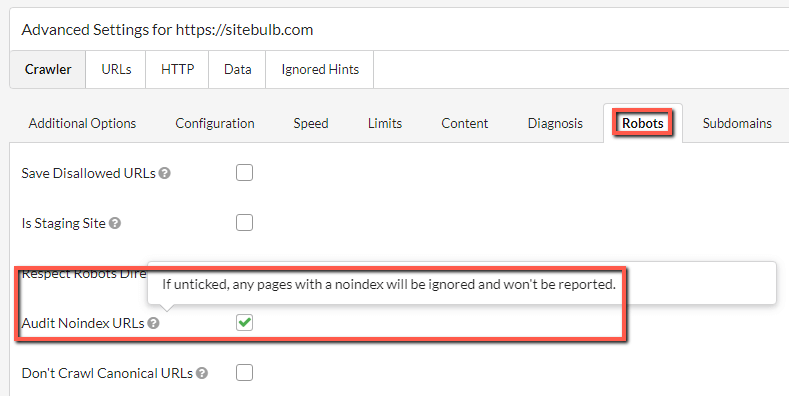
This option will always be ticked by default, which will reflect the normal current default behaviour - if a page is noindex, Sitebulb will still crawl it and report on it in the audit.
However if you untick the box, any noindex URLs found will not appear in the audit at all. It will be as if Sitebulb never crawled them in the first place. And this is the thing that Marshall needed to do.
Aside, if you've been browsing the Advanced Settings recently and felt it was getting a bit cluttered... we agree, and will be working on it in the new year. For now though, you'll need to accept that revolution is messy but now is the time to stand.
Bugs
- In the new Response vs Render report we screwed up the encoding for ampersands on titles and meta descriptions, which caused a few false positives.
- We also somehow royally effed up the XML Sitemap data reporting.
- And finally, we realised that the 2 new redirect Hints we added recently (Internal redirects from trailing slash mismatch & Internal redirects from case normalization) did not have the coverage (%) set. Which meant they weren't being counted properly for the Score calculation.
Version 4.6
Released on 8th December 2020
Updates
#1 New 'Rendering Report' to show response vs rendered
We had a great reaction to 'The Cindy Krum Update' (v4.4) a few weeks back, where we added the ability to see if internal links were added or modified by JavaScript.
At least 3 people told me they liked it.
We were excited to see the public 'round of applause' from undisputed pound-for-pound most enthusiastically energetic SEO on the planet, Aleyda, which, when you look a bit harder, turned out to be nothing more than a thinly veiled feature request... whyIoutta!
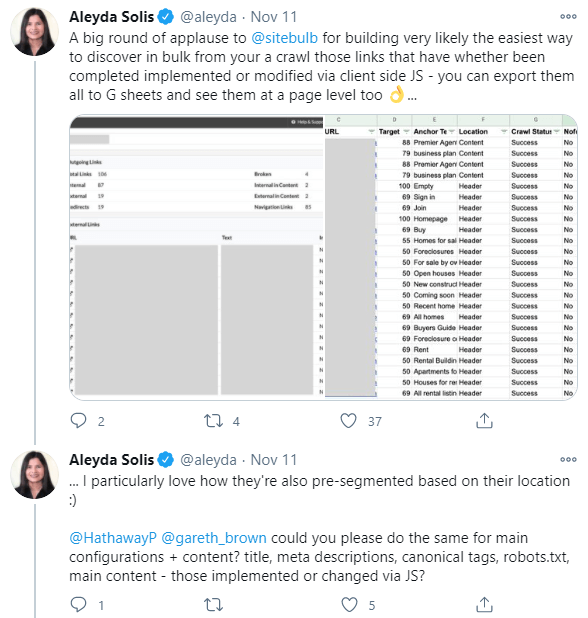
Alas, our frail male egos were so easily massaged, we didn't stand a chance. It was like taking candy from a baby on a diet.
Here you go, Aleyda. God, I hope you're satisfied.
I've already published a comprehensive guide to this feature, which includes some commentary on 'why this is important.'
Humour me, as I riff for a minute about the topic here also...
Our everyday lives are subject to the whimsy of our overlords, from their petty complaints about simple counting to their nonsensically ambiguous advice about normal human behaviour (Non-Brits, see our illustrious leader: "go out don't go out don't go to work go to work if you can don't go out save the NHS"), to their poorly constructed half-truths designed to protect our feeble little minds from the reality of our existence.
These tweets relate to confusion about the claim that Google index in two waves, which they now say was an over-simplification that SEOs read to much into. Whilst I'm not denying that SEO's do have a tendency to read too much into things, I think that these sort of related comments fundamentally misunderstand the purpose of an SEO:

It's our job to not "just assume and get on with it". It's our job to not accept things on blind faith, but to dig and explore and investigate; to test and experiment and verify for ourselves.
"We will not go quietly into the night!"
President Thomas J. Whitmore, Independence Day
This is where we add the most value, dealing between the blurred lines of 'fact' and the realities of data, to understand specific situations for specific websites.
Google's job is to get it right in the aggregate, they don't really care about specific websites.
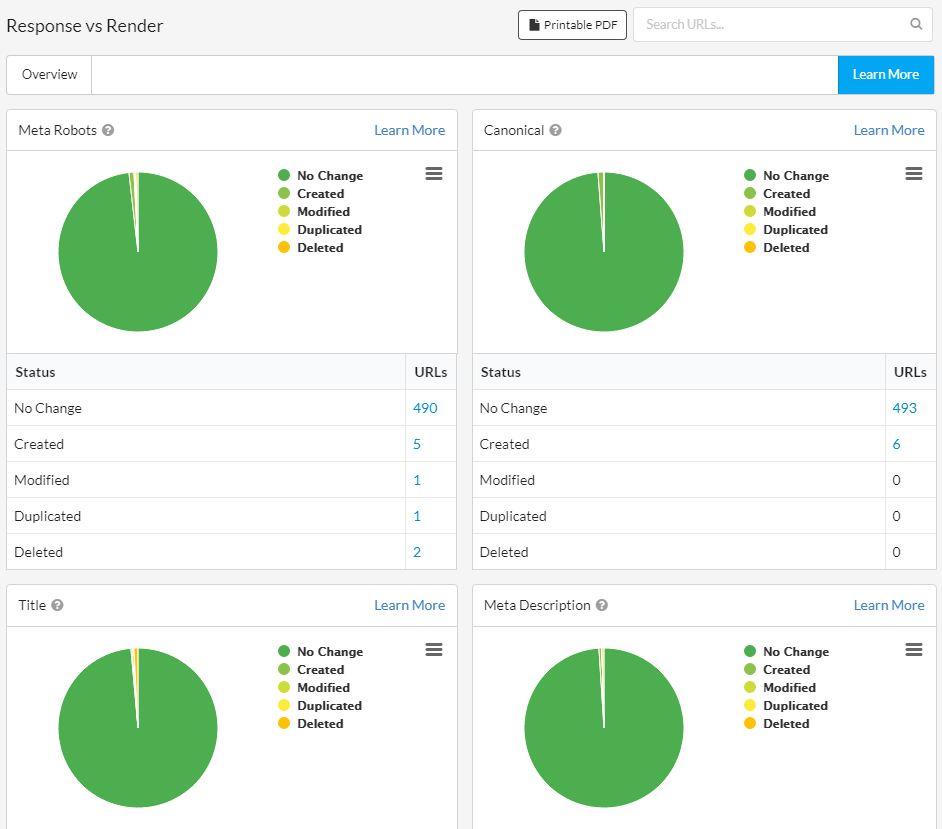
And that's what this report is for. For those sites that you want to better understand where and how the content is changing when the page gets rendered. Moreover, it's for those SEOs who realise this is important, and would rather understand it than just accept things on faith.
If the rendered HTML contains major differences to the response HTML, this might cause SEO problems. It also might mean that you are presenting web pages to Google in a way that differs from your expectation.
For example, you may think you are serving a particular page title, which is visible when you 'View Source', but actually JavaScript is rendering a different page title, which is the one Google end up using.
Sitebulb's Response vs Render report allows you to understand how JavaScript might be affecting important SEO elements, enabling you to explore questions such as:
- Are pages suddenly no longer indexable?
- Is page content changing?
- Are links being created and modified?
Ultimately, these questions might not be important for Google... but they are important for SEOs.
If these things are changing during rendering, why are they changing?
And perhaps more pertinent still: should they be changing?
#2 Improvements to Google Sheets integration
We must thank the extremely helpful William Sears for giving us his time to tell us about his 'real world use of the Google Sheets integration.'
He suggested a bunch of minor improvements that we could to make the process more user-friendly, so we duly obliged. Note that all the changes we made relate to 'All Hints' type exports:

William's wishlist was fourfold:
- Option for ALL hints to be exported to a single spreadsheet, with a single button press.
- Prefix the data in the 'Importance' column with a numeral for logical sorting. For example, 4 - Critical, 3 - High, 2 - Medium, etc... (see below for gif of this in action).
- Similarly, also prefix the Warning Types for sorting.
- Use absolute hyperlinks to link up the 'Hint name' with the sheet reference - so that the worksheet can be copied and used elsewhere without the links breaking.
All of these have now been added*, so if you navigate to 'All Hints', hit the green Export All Hints button and select Export to Google Sheets, you will be presented with a single 'summary sheet' that contains all triggered hints, that is now easy to sort and prioritise, where each Hint name is linked to its respective individual Hint tab, utilising absolute links.
Here's that gif I promised:
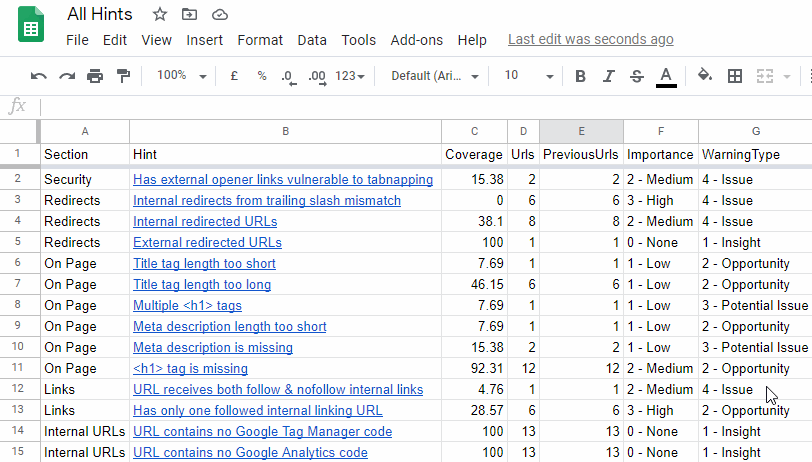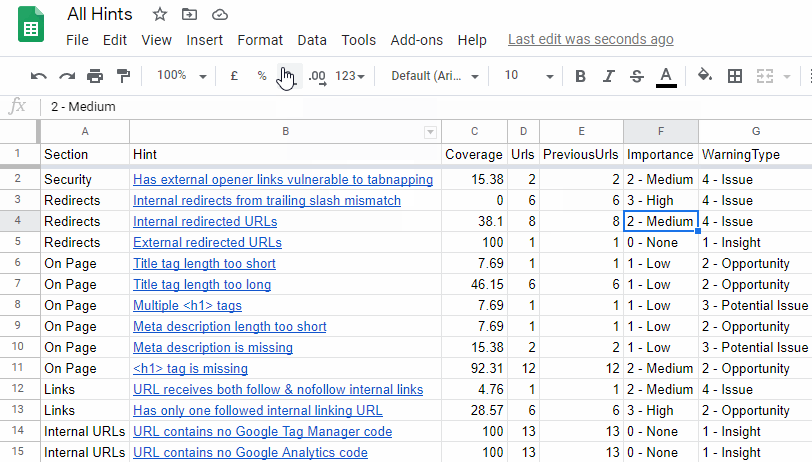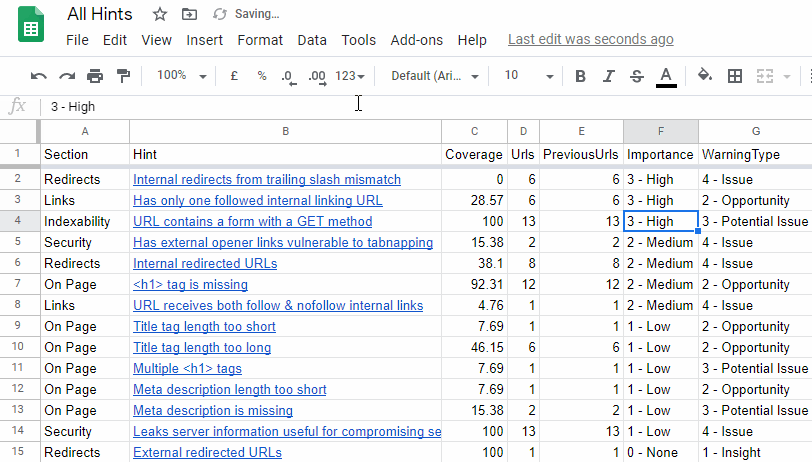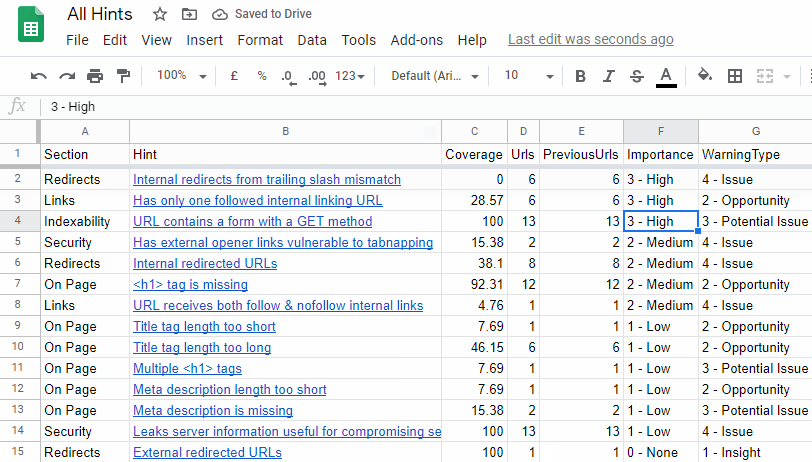
*The asterisk above is legitimate, on this occasion (and not some nonsensical in-joke that only makes me laugh, which is how they are typically utilised on this page). Although we have added all the requested changes, we needed to adjust this one: 'Option for ALL hints to be exported to a single spreadsheet'.
We implemented this, and then when testing immediately hit a problem - with even medium sized sites, it very easily trips the Google Sheets 5 million cell limit - which applies to the entire Sheet, and not just individual worksheets. Consider that there are hundreds of Hints, and any one Hint spreadsheet could realistically trigger for hundreds of thousands of URLs...you do the maths (I refuse to say 'math', don't @ me).
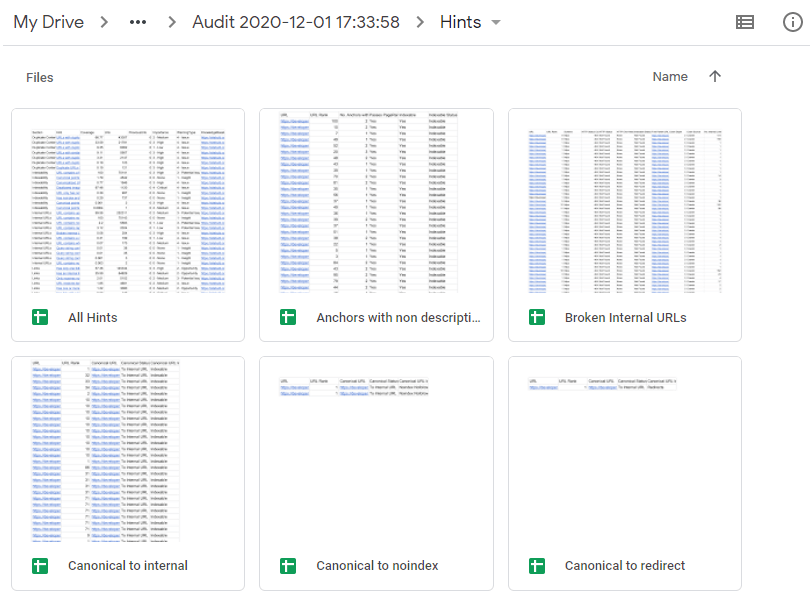
To circumnavigate this took a bit of extra work, and the solution we settled on was to create a distinct Sheet for each individual Hint, and link them up via the main summary Sheet. This required us to first create a 'Hints' folder in Google Sheets, and then populate this with all the individual Hint Sheets.
Once the export is finished, you can either jump into the 'All Hints' summary sheet (as shown in gif above) by clicking View Google Sheet or you can view the folder which houses all the individual Sheets by clicking Google Drive Folder.

The Hints folder contains the 'All Hints' summary sheet, and then all the individual Hint Sheets:
Bear in mind that the 5 million cell limit STILL APPLIES, so if some Hint spreadsheets run into millions of rows, they will be truncated. To understand more about how the data limits work in practice, check out our Google Sheets documentation.
#3 URL Lists now ordered by crawl order
I daresay that folks will like this improvement yet not actually notice anything has actually changed, like the Netflix auto-queue seamlessly starting the next season of The Good Place, without you even realising the last one has ended.
But change has occurred. URL Lists used to show an annoying mish-mash of URLs, often with 301s or bloody HTTP URLs showing up first. It has actually pissed me off for years ('I just want to get to the fucking homepage!'). I mentioned it to Gareth and he was just like 'sure, we'll just order by crawl order, easy.'
FML.
Bugs
- On bigger audits (like, hundreds of thousands of URLs type big) it could take absolutely ages to generate the sampled data for site visualisations, which was starting to piss people off. We've made it a lot faster now.
- In 'The Cindy Krum Update' (v4.4) we added a new Hint for internal redirects due to case normalization, but this was erroneously also including http -> https redirects in the URL List.
- Fixed Sitebulb so that it doesn't support nested XML sitemap index files. It previously did, but since Google can't handle them, we deliberately downgraded Sitebulb to mirror their feeble tech.
- The PageSpeed Hint 'CSS content is not minified' was leading to an SQL error when you clicked to View URLs. This is because Sitebulb was trying to load in a column which does not actually exist. Stupid robot (not a robot).
- URL Exclusions also now include page resources - it only previously worked on internal HTML URLs. Whether this is technically a bug is debatable, but I would rather not have this debate.
- Users (or... at least 1 user) was getting confused by the two 'export' buttons on URL Lists. The one at the top is pre-generated and does not reflect any column changes, sorts or filters you have applied to the data - whereas the one on the right DOES reflect this stuff. We're not currently sure if it is only this singular user who gets confused by this, or our entire universe of users, so while we try and figure it out we've made an imperceptible adjustment to the shade of green on the top export button. This is how world class UX works, people.
- Improved the 'crawl numbers' when doing pause/resume on bigger audits.
Version 4.5
Released on 6th November 2020
Bugs
We've got a new feature for you today! Well, ok, it's not a new feature, it's an old feature we accidentally removed. But these days it is totally acceptable to tell bare-faced lies. WE HAVE A NEW FEATURE!
- We *ahem* accidentally removed the Live View from URL Details, which fetches the URL 'live', renders it and compares the rendered HTML to the source HTML. It's new. Brand new. And it's a really tremendous feature. No one knows more about Live View than us.
- The 'Images' button was not working when viewing the URL List for the Hint 'Loads oversized images which are scaled in the browser,' which was really quite a bad look.
- You could accidentally break Sitebulb by inserting Content Search rules that included a trailing \.
- Saving PDFs on the Mac was including 'Downloads\' in the filename. Shoutout to Russell 'but all my players got Covid' McAthy for this one, who is much better at spotting bugs than playing (NFL) fantasy football.
- Google Optimize was being accidentally recognized as a Google Tag Manager code, so it was flagging the Hint 'URL contains more than one Google Tag Manager code'. I don't know what to tell you. We found some extra votes for GTM codes.
- If one crawled a site and unticked 'respect robots.txt', when you re-audited the site again, Sitebulb would forget this setting. Which is pretty crappy. If anyone was wondering, it's totally ok to dis-respect the robots rules. What good are rules for anyways?
Version 4.4
Released on 23rd October 2020
Updates
#1 Sitebulb now detects and reports on JavaScript links
This is what happens when two powerhouses of the international SEO scene get together and basically challenge Gareth to figure something out. Thanks Cindy for the awesome idea, and Arnout for the assist.
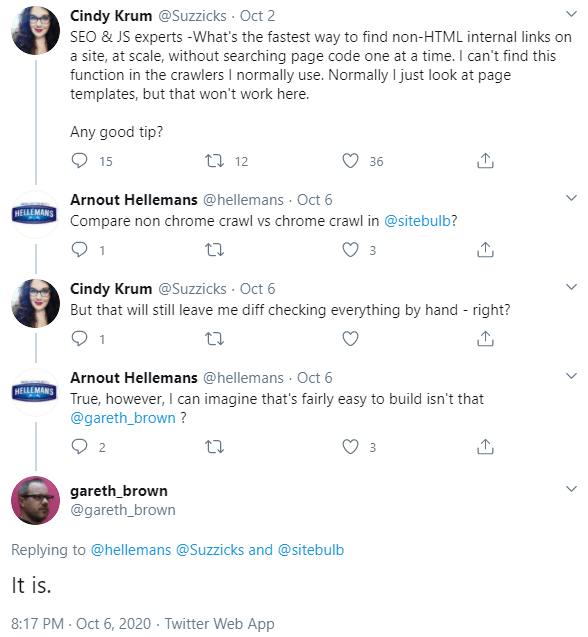
Sidenote: we should all reluctantly credit Gareth for actually doing the work.
So what the bloody hell is Cindy banging on about, and what fix have you built, I hear no one asking. Well, this is all to do with webpages that alter the HTML during rendering, and specifically ones that change links.
I know what you're thinking - don't mess with my links.
Mercifully, most sites don't do this, but when you find a site that does do this, there's literally no way to find links that have been altered by JavaScript, at scale. Until now.
When you crawl with the Chrome Crawler, Sitebulb will render the DOM and parse the rendered HTML, as normal. Now, it will also go and grab the source HTML (as in, before JavaScript might have changed them) and compare all the links between the two.
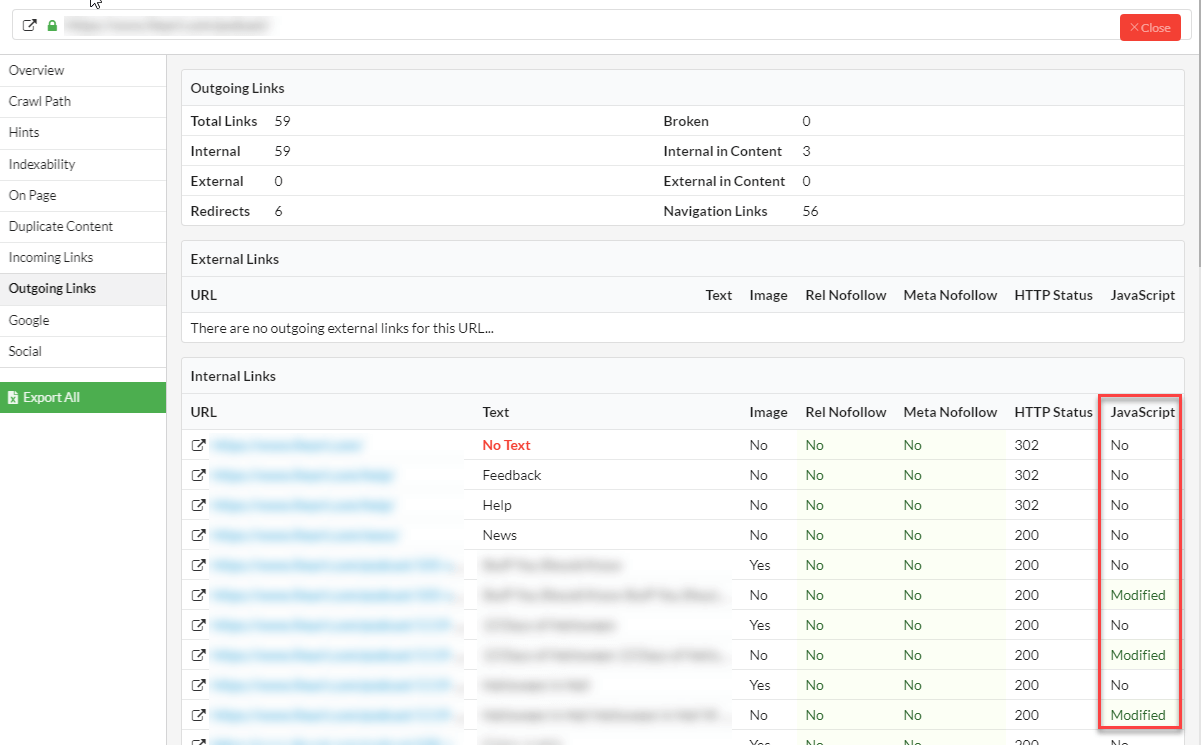
This allows Sitebulb to identify all links that have been affected by JavaScript, and surface these via a new column in the Link Explorer:

The options we have for this column are as follows:
- Created - the link was not found in the response HTML, so it appears that JavaScript created it.
- Modified - the link was found in the response HTML, however JavaScript has modified either the anchor text or the href URL.
- No - not added or altered by JavaScript at all, move along.
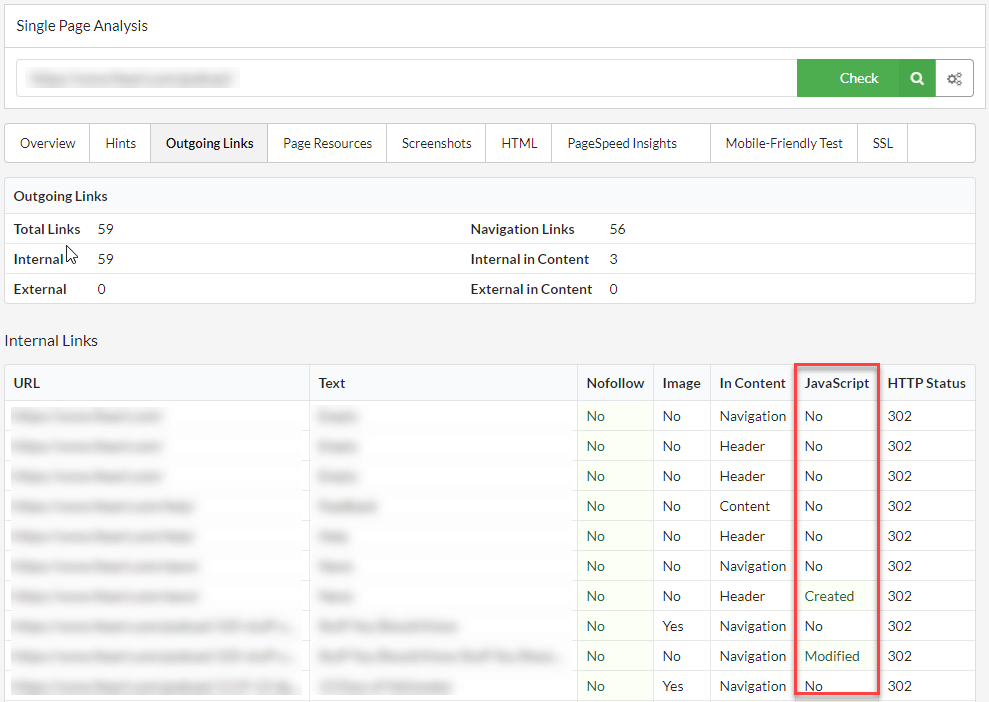
So the Link Explorer allows you to interrogate the data en masse, and if you want to zone in on particular URLs or particular links, you can also see the data listed on the URL Details page. For example:
Independent of any audit, if you want to evaluate a single page, this data is also available in the Single Page Analyser:
#2 Two new redirect Hints added
As a result of more gentle nudging (no, that's not a euphemism. Wash your mind out!) from Cindy Krum, we added a couple more redirect hints:
You know the drill. That twat developer builds a new footer, and includes a link without a trailing slash, or with a random capital letter. The server automatically redirects, so suddenly you have redirected links on every page on the site.
These 2 new Hints just make it easier to isolate these specific redirects issue, which, if widespread (i.e. template based), can be an easy fix that makes a big difference.
Bugs
- A few things looked a bit shit in James Bond mode. In one case, the titles on a report were completely invisible! That's what happening when you put black text on a black background, it turns out.
- We added support for crawling subdomains back in v4.0, but did not think through how self-referencing canonicals would be handled on said subdomain URLs. Sitebulb was claiming they were canonicalized to an external URL! Doh!
- Users were seeing an error "SitemapIndex or UrlSET Nodes Missing" which was due to the sitemap URL taking a long bloody time. We increased the default timeout for XML sitemaps. Page speed is a thing, people.
- When you deleted an audit from a project, the project size was not actually updating in the tool. Sehr frustrating.
- The 'Images missing alt text' Hint was itself going missing, when you re-audited a project from pre-4.3. We looked into it, and it turns out the Hint was just misbehaving. It has been rumoured among the other Hints that it's been bragging about being 'so meta'. What a punk.
- Sitebulb's clever 'entity merging' improvement from v4.1 was a little bit too clever at times, and ended up over-reporting errors. We made it a bit dumber again, lest it get ideas above its station.
- Cleaned up a few more issues being caused by Sitebulb failing to handle x-default properly on sites with hreflang. It was screwing up a few data points, and the fix was boring and complicated (users who reported the error will be contacted individually).
- If you changed your default save location (a la 'Managing file space for your Projects') and then imported an audit, it would not save to the new location, but still the old one. It works properly now.
Version 4.3
Released on 23rd September 2020
Ladies and gentlemen, I give you Gareth 'I'm just going to do a couple of bugs' Brown. 25 tickets later...
Fortunately, most of them related to single site issues only, so you won't find them reported here - but folks that took the time to report the issues, expect an email in your inbox shortly.
Updates
- We have rebuilt a number of the images tables, including fans favourite 'Images missing alt text'.
- This one was my idea. In the Structured Data report, we made the Warnings button orange instead of red, because orange universally means 'not so bad' whereas 'red' is understood to mean 'really really bad.' Some pundits have commented that this makes the tool 'exponentially better' (yes, this was me).
- We actually have Sir Dom of Disney to thank for this next improvement: Scroll to top of the list when clicking between paginated pages in a URL List. Yes, I think I agree with you dear reader, marginal at best. It's no orange button!
- We removed the CSS linter, as it was doing more harm than good in terms of performance. As a result we had to remove all CSS based Hints from the Front-end checks. No bugger looks at those things anyway!
- Updated the Schema.org validation model to version 10, in line with their recent update.
- We added better error handling to the standalone structured data tool, so if a page 404s, it will tell you that it 404s rather than 'we didn't find any structured data'.
Bugs
- Fixed a bug which meant the Code Coverage 'View Wastage' button was literally not working at all (just spinny spinner of death). Only 1 person reported this problem though... do you guys even optimize?
- Last update (v4.2) we added file size to all Projects and Audits, to make data management easier on your machine. Some folks were however seeing this displayed as 'N/A', which is about as useful as see-through wrapping paper.
- I wrote a delightful documentation article entitled 'Managing file space for your Projects' (it's a doozy), in which I heartily encouraged y'all to delete Projects or Audits you no longer needed. Post-publish, we *ahem* realised that deleting in this manner actually did NOT clear up the space on your hard drive. So if you followed my sage instructions... you might wanna do it again.
- This Hint was misfiring: 'Style sheets are loaded after JavaScript resources in the <head>'. If I don't elaborate on this any further, I'm sure you won't just assume that we were searching for the style sheets before and not after the JS. So I shan't elaborate further.
- Fixed a bug with one of the Structured Data pie charts, which, when you clicked through to the URL List, did not show the blue Structured Data button to jump straight into the single URL details. Inexcusable.
- Fixed an annoying UI bug which meant you could only add 50 columns at a time to URL Lists, with the Add/Remove columns function. Now you can add ALL THE COLUMNS! as intended.
- Improved parsing of microdata for deep nested properties, which was causing Sitebulb to mis-report some structured data (don't worry, edge case stuff).
Version 4.2
Released on 16th September 2020
This is the sort of update that newer Sitebulb users will be like 'meh' but older Sitebulb users will be like 'ohmygodthisisgreat.'
New users, take a walk. Old users, enjoy...
Ways and means to manage all the data that Sitebulb creates
Website audits create a LOT of data. Especially big ones.
And especially when you've kept every single audit, for every single client, for 3 years - without ever even thinking about going back and deleting some old audits. Sound familiar? Are you me?
This update is focused on solutions to the 'ain't got no hard drive space left' conundrum. I have actually written a thrilling chronicle on this self-same topic in our documentation area, entitled Managing file space for your Projects.
Since I'm on strict orders NOT to swear in the docs, we'll recount the changes here as well, with a more relaxed vibe ('I'm basically a chilled out entertainer.').
#1 Project list now shows file size of the data
Your Project list now shows the data size of the Project, so you can easily scan down the list of Projects to find the biggest ones:

Mind = blown, right?
So this is the easiest solution to the 'size' issue. Just go and delete the biggest fucking Projects and be done with this whole charade!
But ok, we get it, that client who fired you in 2018 is definitely going to come back from your competitor, they're bound to be receiving terrible service. It is written.
So it's super important you keep all your Projects. BUT do you need to keep all your Audits?
#2 Project page now shows file size for Audits
We've only gone and added the file size there too! Now you can see where all the data storage is coming from, and delete all the worst offenders. When it comes to <CLIENT WHO IS DEFINITELY COMING BACK SOON>, why not just keep the most recent audit, and delete all the rest?

Why not indeed? Because some people dislike making the right choice, and would rather just keep everything forever (See also: Trump supporters).
Ok, well for you lot, we've got something even more exciting...
#3 Change the default save location
If you think I've buried the lede, well, I apologise - I just like to create a bit of suspense.
People actually asked us to do this one, and everything.

PREFACE: Sitebulb is a desktop tool, which means data is saved to your local machine (some people automatically assume Sitebulb saves data to the cloud, likely because it is so gosh-darn beautiful).
Here's the skinny - Sitebulb is set up to save all Audit data to the same relative folder, on every machine. This default save location uses this directory:
- Windows: C:\Users\<USERNAME>\AppData\Local\Sitebulb
- Mac: /Users/<USERNAME>/.local/share
If your main drive is becoming full and you are looking to save space, one option may be to save data to a different partitioned drive, or an external hard drive.
Also, you may wish to just do this anyway - nothing to do with saving space. You'd just rather have all your stuff in a particular place. This works for that philosophy also.
In order to change the default folder, you need to adjust the 'global settings' that govern how Sitebulb runs by default for every Project.
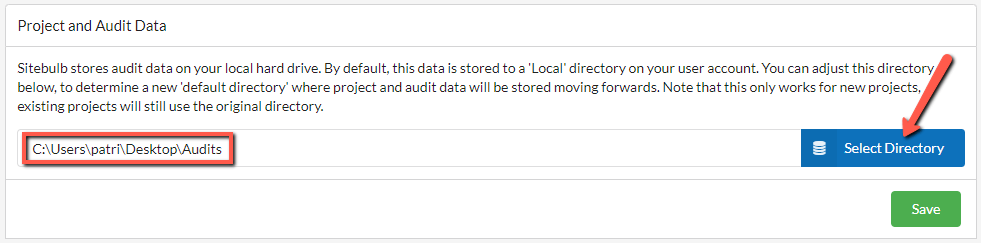
From the top navigation menu, choose the 'Settings' option.

From here, the 'Project Data' tab allows you to control where Sitebulb stores your audit data, on your computer.

In order to change the default file location, simply click the blue button, choose the appropriate directory, then hit Save. Note that this does not move pre-existing Project/Audit data, but will become the new default location for all new Projects you add.
I expect there are literally handfuls of people getting all hot and bothered as they read this, anxious to try it out. Before you do, take a moment to consider the intentions of this setting and also the devices we have tested it on (with resounding success):
- Different folders on the same hard drive
- Shiny new SDD external hard drive
- Shitty old external hard drive
- USB flashdrive(!)
- Dropbox
Is has not been tested on a network drive - and we do not recommend you use this on a network drive. Sitebulb has to perform many thousands of read/write actions in short order - if you subject it to your ponderous shared network drive, I expect you'll be sorry.
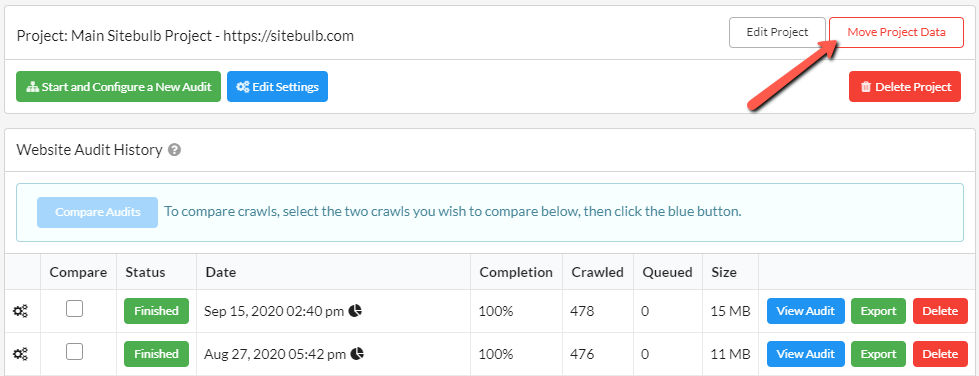
#4 Move existing Projects into a different directory
The option above allows you to change where Audit data is stored for new Projects. However, you may have a particularly large Project that is already stored in the original default save location, which, to reasons unknown to you, your client does not wish you to delete (let us never question their enduring wisdom).
In this situation, the best option might be to move the Project to a completely new location - such as an external hard drive. This way you can get it out of off your hard drive until such a point that your client realises they no longer need it (or realises they no longer need you...).
To make the magic happen, go to the Projects page and click the Move Project Data button:
This will open an overlay window that allows you to choose a new directory for the Project data to be stored. Again, this can be anywhere that your computer has access to at the time - a partitioned drive, an external drive, or a 'smart workspace' like Dropbox.

This may take a few minutes, so do not move away from the page. Just let Sitebulb do it's thing.
Now, if you are moving a particularly large audit, and/or moving it onto a particularly shitty piece of hardware, perhaps don't do this right before you need to use Sitebulb to produce another client audit that was actually due yesterday. If I see support requests of this nature, don't think I won't send a passive aggressive reply and post subtweets that are only meaningful to me.
Once your Project has been moved, you will see a notice on the Project page for the new save location of this audit.

A byproduct of this process that is not particularly intuitive is that any new Audits you run within this Project will also save to the new location.
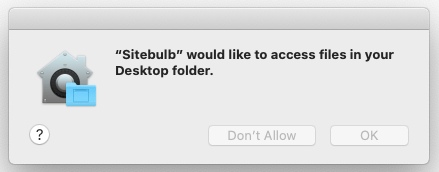
Unfortunately, I need to add a small addendum for the Mac users among you.
If you move a Project on the Mac, before you are able to open any of the Audits within that Project, you will need to restart Sitebulb, and then your Mac will ask permission when you try to open one of the Audits:
And just so we're clear, this is only a minor inconvenience. I don't think it's fair to conclude that Macs are shit and should be immediately replaced with a (far superior) Windows machine.
To recap;
- You can now easily see the data size for Projects and Audits - delete some damn data already!
- You can now change the save location for all Audit data, moving forwards.
- You can now move existing Projects into other locations, such as an external hard drive.
- You should throw your Mac in the bin and buy a Windows machine instead.
Version 4.1
Released on 27th August 2020
Improved the Structured Data analysis
Since we launched v4 we've had tons of great feedback from you beautiful people, in particular regarding the structured data feature.
But we've also had plenty of ideas and suggestions for how we can make it better.
Unlike normal, most of these were not completely shit ideas from people who want us to build a fix for their one specific use case that only ever affects one website, and is not even really for a client site it's actually just their mum's friend's site that they agreed to help out on and now massively regret it.
In particular, we received excellent advice from Dave Ojeda and Tony McCreath, who both took significant time to let us know how they think we can make the tool more complete. We sincerely thank you both.
The BIG thing that we've done revolves around unique entity identification - Sitebulb will now identify unique entities. And it will merge entities that use the same @id, into a single entity.
These are non-trivial concept, so I'll give you a quick bullet point for each, then explain in more detail below;
- Unique entity identification - Sitebulb now understands that 500 instances where an entity is referenced does not necessarily mean there are 500 unique entities. There could be 500 references to a single entity, for example. Sitebulb can now accurately pick this apart.
- Merge entities - Sitebulb will now stitch together references to the same unique entity, even if they use separate bits of markup on the same page.
#1 Unique entity identification
This will be easier to explain with an example. We'll use une pomme you know and love who's unafraid to step in... apple.com.
On a sample audit, this is what the old version would show you:

~1,900 different 'organization' entities? That sounds like a lot of organizations... for a single organization like Apple.
This is what you see on the new version:

Now we're getting somewhere. Just 2 organization entities, referenced on ~1900 instances.
Clicking the blue '2' lets us see these:
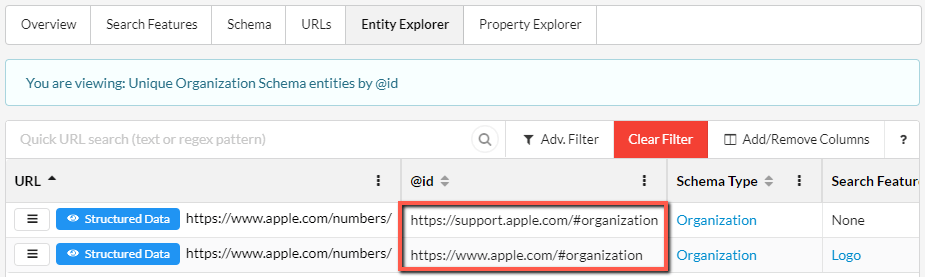
This opens up a filtered view of the Entity Explorer, and we can easily see the two different organization entities, identified by the two different @ids.
Aside: if you are unfamiliar with the @id property, this is what's known as a 'node identifier', and it can be used to reference specific schemas without needlessly repeating data.
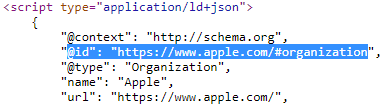
Note that if the @id property is NOT present, Sitebulb will still try to identify unique entities, it is just slightly less good at it.
Finally, note that for existing audits with Structured Data, the entities will all be listed as '0' - you'll need to re-audit the site in order to see the unique entity data.
#2 Merging entities
In terms of merging entities, this comes into play when you have data regarding a single entity loaded onto the page in more than one place (e.g. from two different sources).
Previously, Sitebulb would see this as two separate, disconnected entities. Now, if it can determine that the markup is referencing the same entity, it will merge the data into a single item.
On lots of sites this won't be the case, so you won't have experienced this as a deficiency in Sitebulb's reporting. Tony McCreath alerted us to this happening on his client site Looma's (online cake delivery!!).
Let's use their macarons page as an example:

Aside: for many years I thought these used to be called macaroons and someone just changed the name one day. Turns out macarons were always macarons, and macaroons are just a completely different biscuity-thing.
This is how Tony described the review markup on this page:
"This is an interesting page as Yotpo dynamically add reviews and then we rewrite what they add so that the data links up correctly. Sitebulb shows two separate products. In reality these are separate bits of markup representing the same Product. This is done via the use of a common @id."
Previously, Sitebulb was treating this as two separate products, and flagging a bunch of errors on the product reviews portion as it looked like an incomplete data set.
The product portion looked like this (note the highlighted @id):

And the reviews portion looked like this (note the same @id and a pile of errors):

To solve this, we now merge the data on the @id, which forms the complete product. This means that Sitebulb no longer thinks that required properties are missing, which in turn means that the errors are not flagged.
So in 4.1 this same page shows as one complete product, with no errors:

We even now pull out the @id (where present) to show the unique identifier more clearly. As well as merging two or more entities, Sitebulb will also build up any nested entities by @id too.
Improved 'single page view' for structured data
Either using the standalone structured data checker tool (which checks a single URL) or drilling down into the URL details of an audit will give you a single page structured data analysis.
Much like Google's old Structured Data Testing Tool. Except neither discontinued nor completely shit.
Previously, this provided one single view, but now we have split it apart into 3 tabs to show you what is really going on with the structured data.
The first tab shows all the Google Search Features found:

The second tab shows the root Schema entities:

The third tab shows all the individual entities:
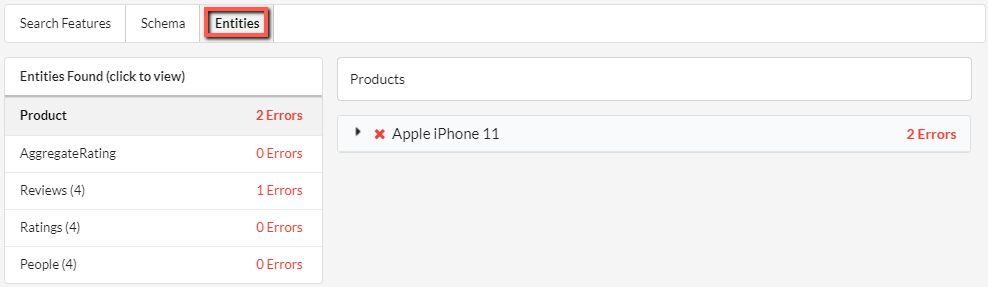
These views give you the flexibility to dig into the data as you please.
Other small improvements to structured data
A few other small things we changed regarding the structured data feature:
- Updated how the tool parses certain nested objects.
- Relaxed the rules around PostalAddress as we had set them to be too harsh, and errors were being flagged when they should have been warnings.
- The expected type checking has been relaxed to fall in line with Schema.org's guidelines. An expected type can now also be text or a URL.
Added 'bulk upload' to content search feature
In our v4 update, we added 'Content Search', which allows you to specify a word or phrase for Sitebulb to search for on every page of the site.
Of course, lazy bastard SEOs came back to us with 'but what if I want to search for lots of words at once, surely I don't need to add them in one by one? SURELY?!'
Well, actually, you did need to, but now you don't. Just for you, Shirley, we added this button:

And it works exactly like anyone with a brain would expect it to work. Write your words/phrases, one per line, or just copy/paste the living daylights out of it.
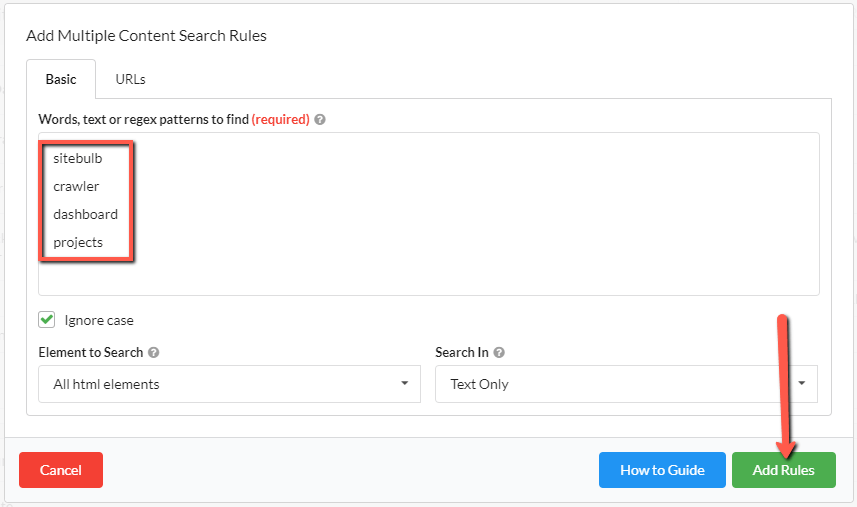
When the report is complete, each rule will display as if you had entered them one by one:

And yes, before you ask, you can just dump thousands of words in at once. Note that if you do this, the best way to access the data is to use the green Export All Search Data button you see in the image above. You CAN access the data via the URLs tab, but it will only load 50 columns in at a time, so you would need to do a lot of add/removing to see what you want. Just use the export already.
XML Sitemap build from URL List
Every so often, a customer sends through a question like, 'hey how do I do this one thing please?' and it turns out they are asking for something that Sitebulb doesn't do, and it is something that we would never ever in 1000 years have thought to add.
This little update is one of those things.
Here is what this customer wanted to do:
- I want to crawl my entire site.
- Using the URL Explorer, I want to define a very specific list of pages (e.g. 'product pages').
- With a couple of clicks, I want Sitebulb to generate me an XML Sitemap including only those pages.
So this is exactly what we built:

The XML Sitemap builder allows you to include priority and changefreq attributes.
using Cloudflare and SRCSET tags results in a bunch of erroneous/broken crawling.
Bugs
- As reported by Jono in what might just possibly be the most thorough support ticket ever, in which he told us both what the problem was and why it was happening, Sitebulb had a bug such that 'using Cloudflare and SRCSET tags results in a bunch of erroneous/broken crawling.'
- URL Details view would occasionally lock up, on websites with particularly shitty HTML. This was because in the background it was trying to load up the 'Live View', and it was struggling to process the HTML diff (due to the aforementioned dogshit HTML).
- 'Mark as fixed' would not persist if you closed down Sitebulb then opened it back up again. Whilst this sounds utterly horrendous, in our defense it would only happen if you just ticked 'fixed' and did not enter a description in the description box (so only ~95% of all user instances).
- On some webpages the magnificent 'point and click' selector for content extraction would work sub-magnificently. That is to say, it would not work at all.
- If a webpage contained SVGs with titles, Sitebulb would trigger the Hint 'Multiple title tags.' Stupid Sitebulb!
Version 4.0
Released on 3rd August 2020
I'd like to start the v4.0 release notes with an apology. Below you will find *ahem* 4000 words of incomprehensible drivel and mediocre jokes, and it's too many damn pages for any man to understand.
In case you value your time too much for this malarkey, I made you a launch video as well:
Schema + Rich Results Extraction & Validation
So here we are. We FINALLY got the message, y'all wanted us to build this thing (over 300 upvotes on our feature request page).

The reason it took us so long is that we are not particularly good at doing things by half. We knew that if we were going to do this, we owed it to ourselves to do it properly.
So we spent AGES on it.
However, being British, it is impossible for me to say that something I was even tangentially involved in is anything more than 'ok'.
I'll just leave this here instead...

Since we're too bashful for self-promotion, we'd love it if you could also share on the socialz to help us out.
This is what Sitebulb can now do for you:
- Extract structured data marked up with JSON-LD or Microdata format.
- Validate against Google's Guidelines for the 29 Search Results Features.
- Validate against Schema.org data model for all other structured data.
- Aggregate errors so you can pick out template-based problems.
Of course, you'll get some pretty charts to make your client reports look sweet af, and the historical trendlines show changes over time, allowing you to demonstrate improvements as recommendations get implemented (*ahem* or not).

Validation using Google Guidelines
Ok, now for a word on validation. This is how validation has worked for as long as anyone cares to remember:
SEO: "Mr Client sir, I'm afraid your structured data is broken, it fails Google's Rich Results test."
Client: "Hmm, are you sure?"
SEO: "I made you a screenshot, here."
Client: "I just tried it and it passed. What are you talking about?"
SEO (panicky): "Wait, what?? What tool did you use?"
Client (reading): "Google Structured Data Testing Tool, it says here."
SEO: "Oh! Ignore that. It's old, they're getting rid of it anyway."
Client: "But why does it pass one tool and not the other?"
SEO: "That's not important. The important thing is that I'm right."
Client: "I'm patching the developer in. He wrote the code."
Developer (sulking): "Oh, it's him again. What does he want me to do now?"
Client: "He says your structured data is wrong."
Developer: "It is not! I followed Google's guidelines to the letter!"
SEO (smug): "Look, it fails Google's Rich Results test. I have a screenshot and everything."
Developer: "I just checked, it's still showing in the search results. Have we received any warnings in GSC?"
Client: "GSC?"
SEO & Developer: "Webmaster Tools!"
Client: "Oh. No. Not got any warnings."
Developer (satisfied): "See. Nothing to worry about."
SEO: "But. But my screenshot..."
The question consistently boils down to: 'which Google tool is telling us the truth?'
Google themselves deem their documentation as the ultimate source of truth:
So in Sitebulb, this is what we use. We painstakingly built our own data model, which validates against Google's Guidelines. And when I say we, I mean Gareth.
Here's what it looks like:
So what this means is that inevitably, Sitebulb will sometimes disagree with Google's testing tools. But that is only because their testing tools disagree with their own guidelines.
Most often the thing we have seen is that Sitebulb will point out that a required property is missing (because Google's docs say it is required), but Google will still give it a 'pass' on the Rich Results test. With that sort of thing, our feelings tend to err on the side of:
- Better safe than sorry.
- Google have a track record of changing the goalposts without warning. So see #1.
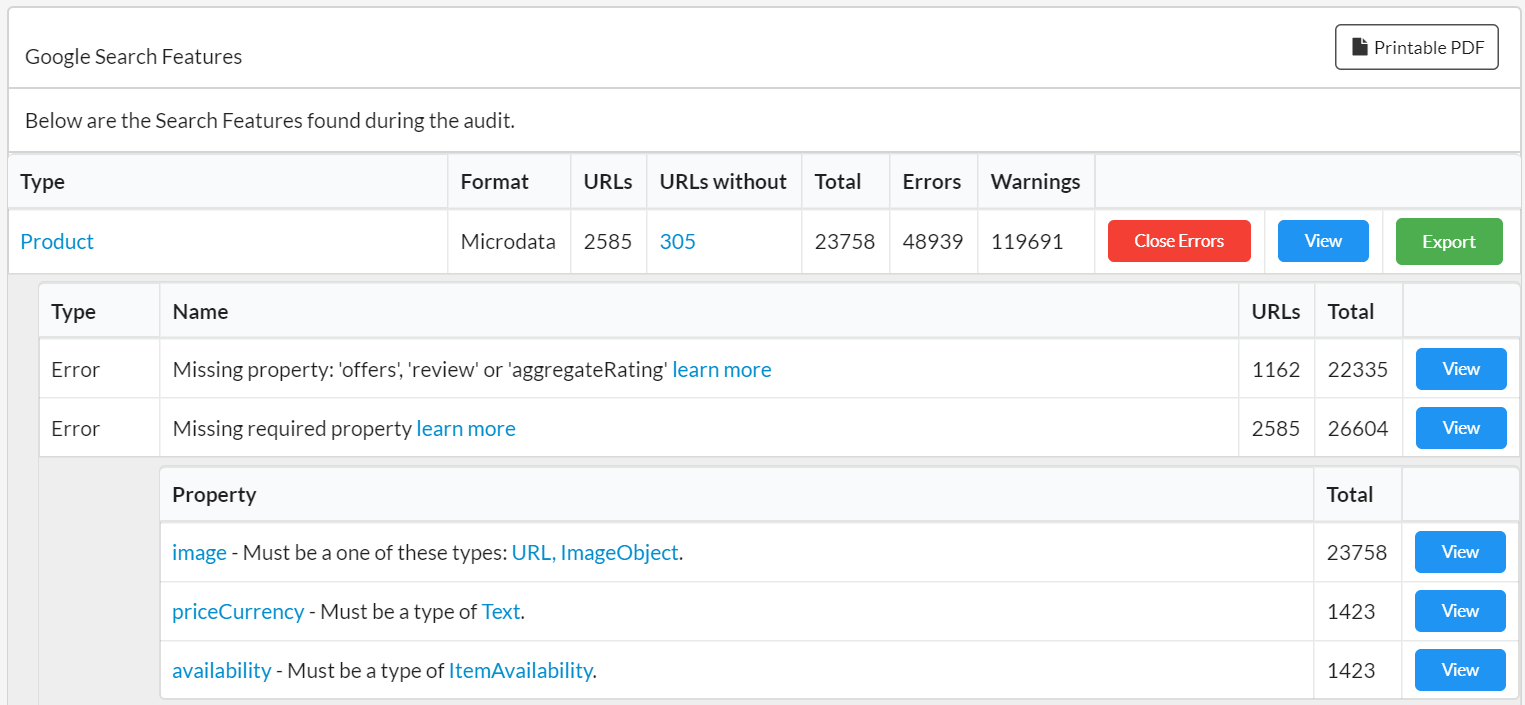
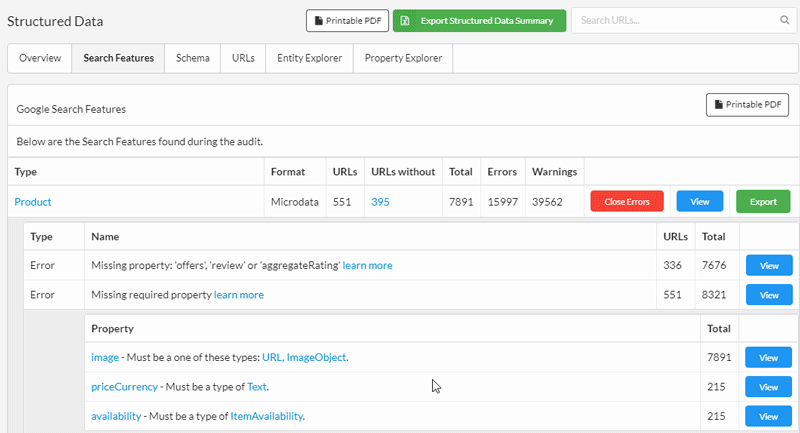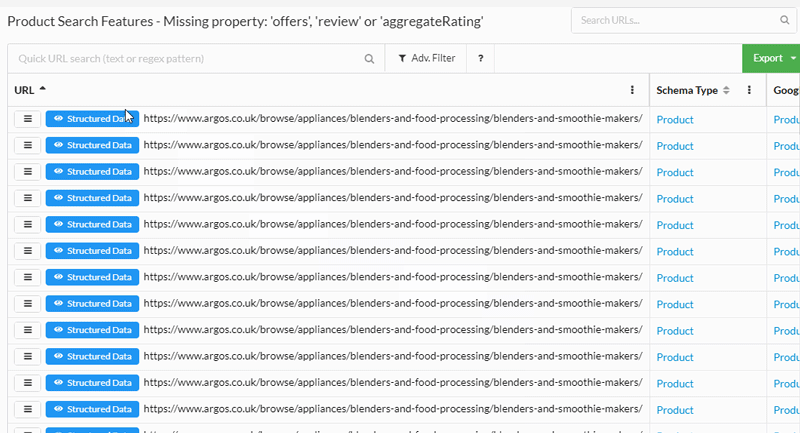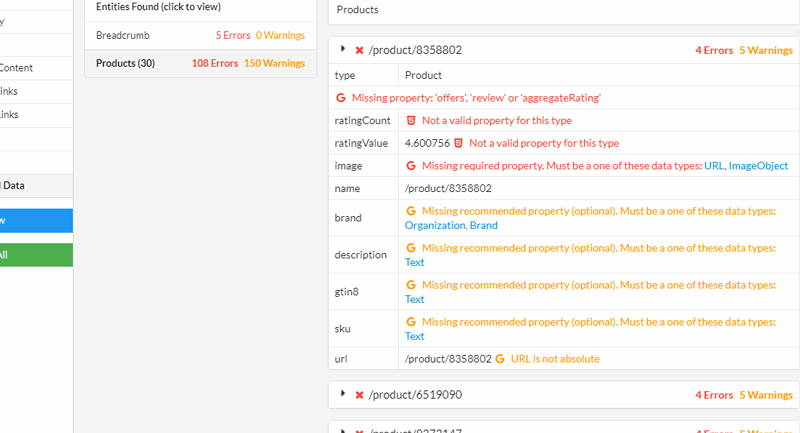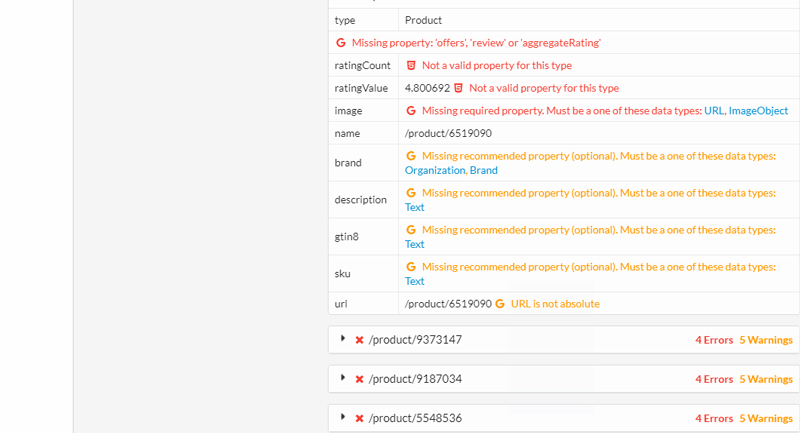
Aggregated Errors
So here's the other problem with structured data validation - issues typically occur on page templates, yet all the reliable testing tools will only take one page at a time.
Identifying and fixing problems at the template level can enable you to resolve problems with a lot of pages all at once.
For this reason, Sitebulb aggregates issues across multiple pages, so you can pick out the specific template error and list all the pages affected.
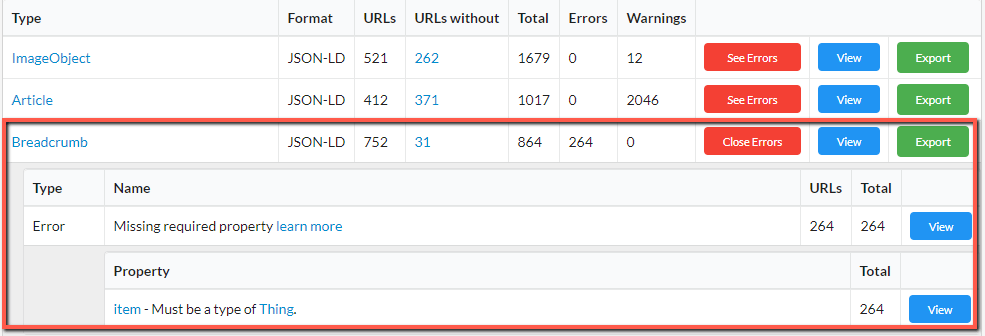
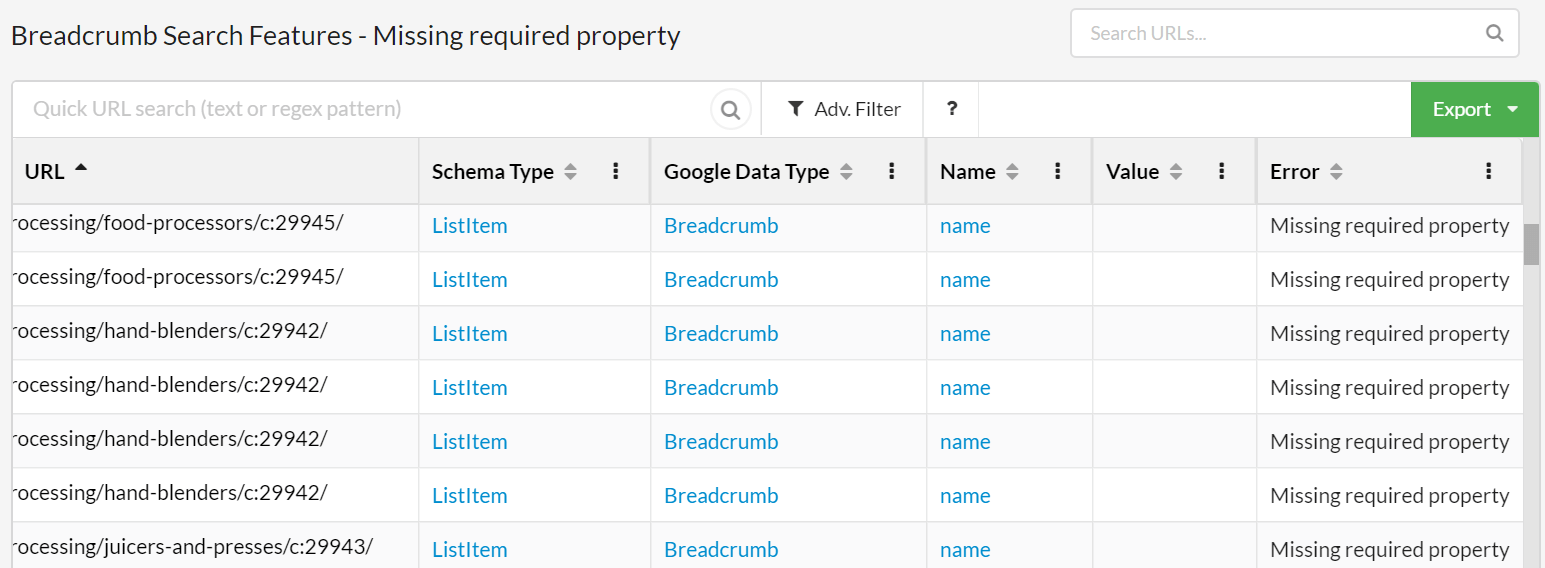
In the example below, there are some errors with 'Breadcrumb'. Clicking the red See Errors button allows you to...see the errors. In this case they all have the same error - they are missing the required property 'item.'
Whilst you probably want to report issues as a template level, you will also probably want to investigate further and pick out some specific examples to send to your clients.
Everything can be drilled down in Sitebulb, so you can check the data in a list:
Or you can explore at a URL level and dig into the markup, with all the issues and errors highlighted for all entities found on the page.
Schema.org Validation
Fixing structured data issues in order to satisfy Google's search feature requirement is typically the number 1 thing that SEOs wish to do, but there is a whole ecosystem outside of Google that can make use of structured data.
For instance, new technology like the Semantic (*mumble*) Connectorising (*mumble*) Graphalizer.
Ok, ok - it's mostly just Google. BUT Google don't let us know when they are adding stuff so better to be ahead of them by sticking to the standard. And some people just like to mark up everything in sight.
This is why Sitebulb also collects and validates all of your Schema.org markup, validating against the published Schema.org documentation.

This also means you can start to use the data in more interesting ways. For example, finding your products with the most reviews or best review ratings. Sitebulb has a built-in entity explorer and property explorer, so you can interrogate the data to unearth interesting opportunities.

Write and fix structured data markup on the fly
As is their wont, Google managed to piss a lot of SEOs off recently, by announcing that their Structured Data testing tool is being shut down.
You may already be looking for a new method for building and testing your structured data markup in anticipation.
Sitebulb has this covered too.
From the tools menu at the top, choose the Structured Data Checker tool, which will check and validate structured data on any URL or code snippet you enter, allowing you to quickly iterate and re-check as you go.

That brings us to the end of our structured data feature tour. Oh I nearly forgot to tell you how to switch on the structured data extraction: you tick a single box during the audit setup. Done.
And finally, let me direct you to our documentation area, which will tell you all you need to know about structured data with Sitebulb, and probably more.
Point-and-click Content Extraction
It may also seem like we’re a little late to the party when it comes to content extraction, since practically all the other major crawling tools have it already.
In fact, we were early, developing a 'custom scraper' feature back in 2014, for our first product, URL Profiler.
And so we know what 5 years of support requests look like for this feature…
- How do I figure out the CCS selector please?
- What is the XPath to find the price on these pages?
- Why doesn’t it work on <INSERT RANDOM AngularJS> website?
- Who, exactly, is Reg Ex?
And it’s not just the support requests, it’s also all the documentation around these features. Go check out any how-to guide for custom extraction, you’ll see a very familiar intro… 'before we can show you any of the good stuff, let’s have a quick 1000 word primer on the fundamentals of XPath.'
We just figured that THERE HAS TO BE A BETTER BLOODY WAY OF DOING IT THAN THIS.
And there is.
Without further ado, I present to you, Sitebulb’s Content Extraction (AKA 'Custom Extraction in the 21st Century').

Point and click baby.
Our workflow addresses all of the major pain-points that usually accompany this feature:
- Load in a test URL into the visual selector window (also works with JavaScript frameworks).
- Point and click the element you want to scrape.
- Give the datapoint a meaningful name.
- Check the 'Test' tab to ensure it is working as you expect.
This means it works on any website you throw at it. It means you don’t need a degree in advanced Regex to figure out the extractor. And it means you don’t need to crawl the website 37 times in order to test your selectors.
The results are presented very clearly for you in the new report 'Content Extraction', with both an overview of the data found:

And the raw data itself in a URL List:

As always, you can filter the data or add/remove columns, allowing you to mix and match crawl data with your content extractions.

Advanced usage (Regex and whatnot)
The point-and-click functionality means that anyone can get going with content extraction, but in general we consider content extraction a relatively advanced feature. We are a caring bunch here at Sitebulb, and we were conscious that this feature also needs to cater for the 7 SEOs worldwide who are competent in Regex, so we have some more advanced functions.
We have a complete Advanced Guide in our Documentation, so I won’t cover all the ins and outs here, but I do want to whet your appetite with some tidbits:
- Regex scraping IS available, but we offer it within the CSS selector path. This means you don’t need to write regex to search the entire document, making it a lot more user friendly.
- You can also pull out a specific Regex group from your pattern.
- Use a range of in-built 'operations', like matching the first/last/all items, performing a count, or checking that an element exists.
- Match on different data types, to automatically extract URLs, phone numbers, email addresses etc... - WITHOUT writing complex Regex patterns - let Sitebulb do the dirty work.
- Apply specific 'URL Matching' rules, to only perform the content extraction on specific pages. This means, for instance, you can instruct Sitebulb to crawl the entire site, but only grab the pricing info from the /product/ pages. This saves on collecting spurious data you won’t ever use, saves on processing during the crawl itself, and saves on data storage on your hard disk.
At this point I feel a gif to show off some of this stuff is the least you deserve:
We'll be publishing a bunch of real-life examples of using this data for good in the not-too-distant future. In the meantime, our docs contain a bunch of examples and screenshots which explain the ins and outs of this feature.
Content Search
The logical bedfellow to content extraction is of course content search. For the uninitiated, this basically means 'search every page on a website for a specific word or phrase.'
Such unsuspecting cherubs may also fail to appreciate the value of such a feature, so let me illuminate. The results of the search allow you to then filter pages based on whether or not they contain certain words.
For example:
- Check if ecommerce product pages contain 'out of stock' messaging.
- Check which pages reference a particular brand name or company name.
- Understand which pages mention certain target keywords (for building internal links).
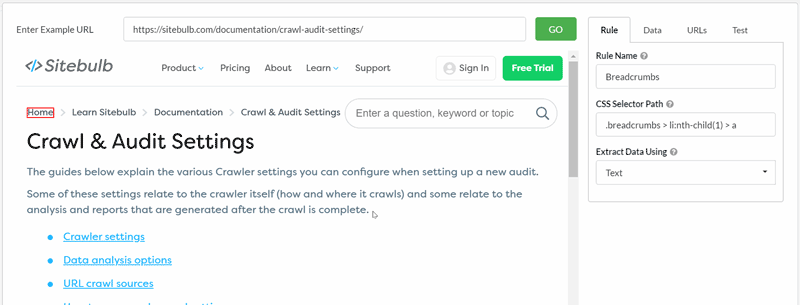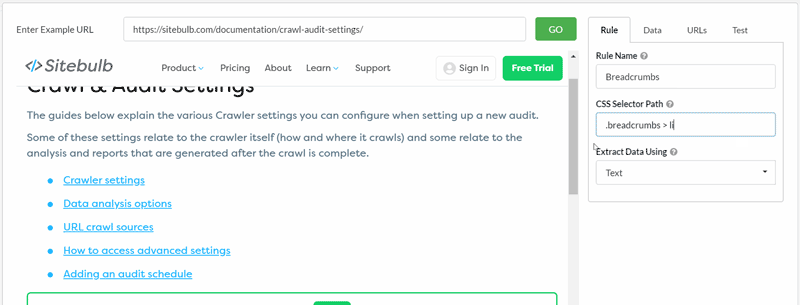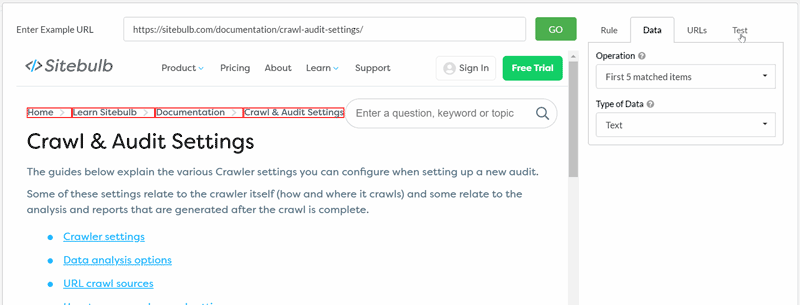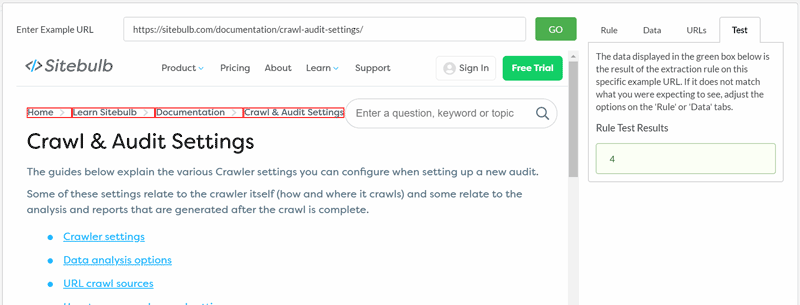
For a basic search, all you need to do is enter the text and hit 'Add Rule', and that's all there is to it.
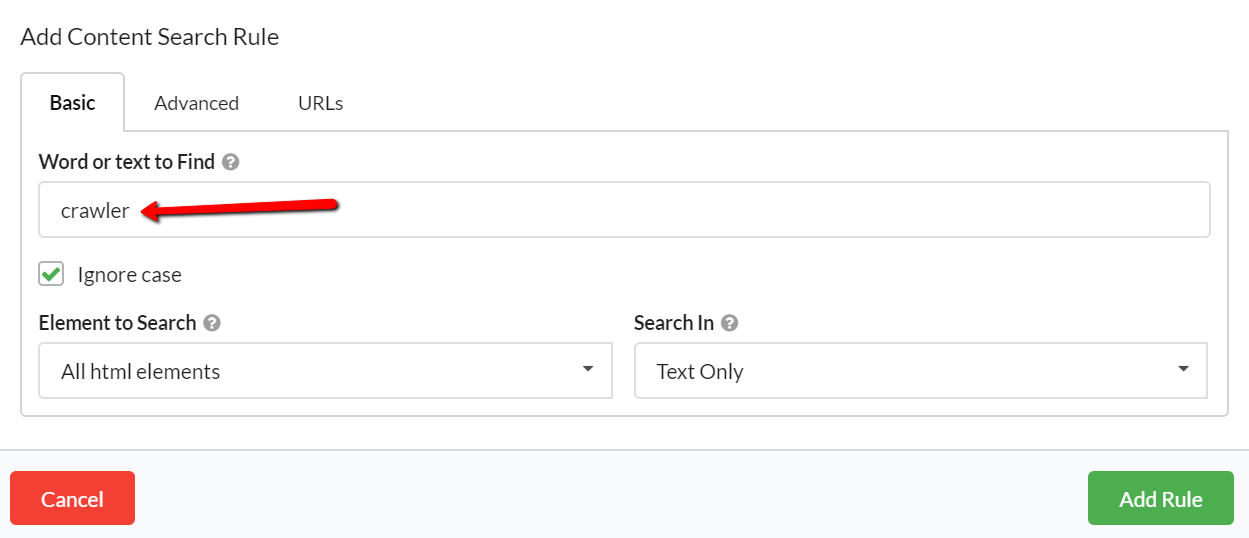
Once you've added your rule, you can stop there, or just keep adding more rules. You will see all your rules in the audit setup page, ready for you to start the audit.
For example, if we wanted to crawl our site and understand how often we reference Sitebulb as a 'crawler' vs a 'website auditor', we could set it up like this:

There is no limit to the number of rules you can add, so collect all the data you need.
Once your audit is complete, you can access the data report using the left hand menu.
The Overview will show you details of the data totals for each different search phrase:
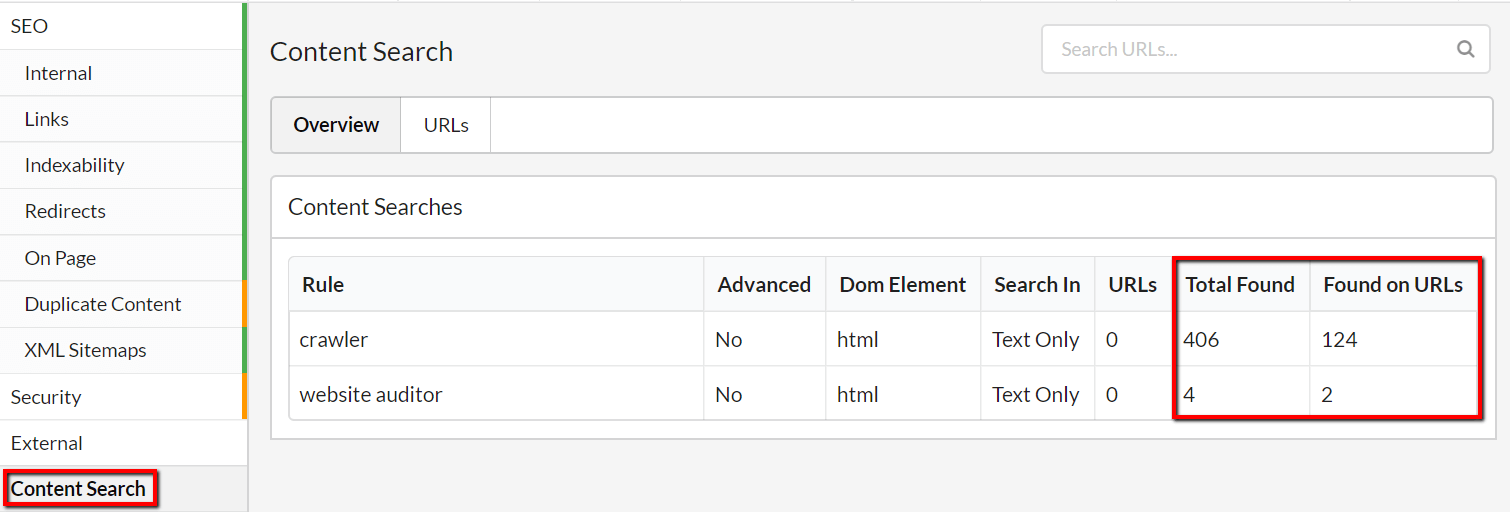
The two data columns tell you slightly different things:
- Total Found = the total number of instances that Sitebulb found the phrase, even if some of them were on the same page.
- Found on URLs = the number of unique URLs that Sitebulb found the phrase on.
Without even analysing the data in detail we can already see that 'crawler' is dominant.
To see the detail of specific URLs, we need to switch to the URLs tab, which shows the URLs alongside columns headed by the text/phrase filters. The numbers in each cell relate to how many instances of the phrase were found on each page.
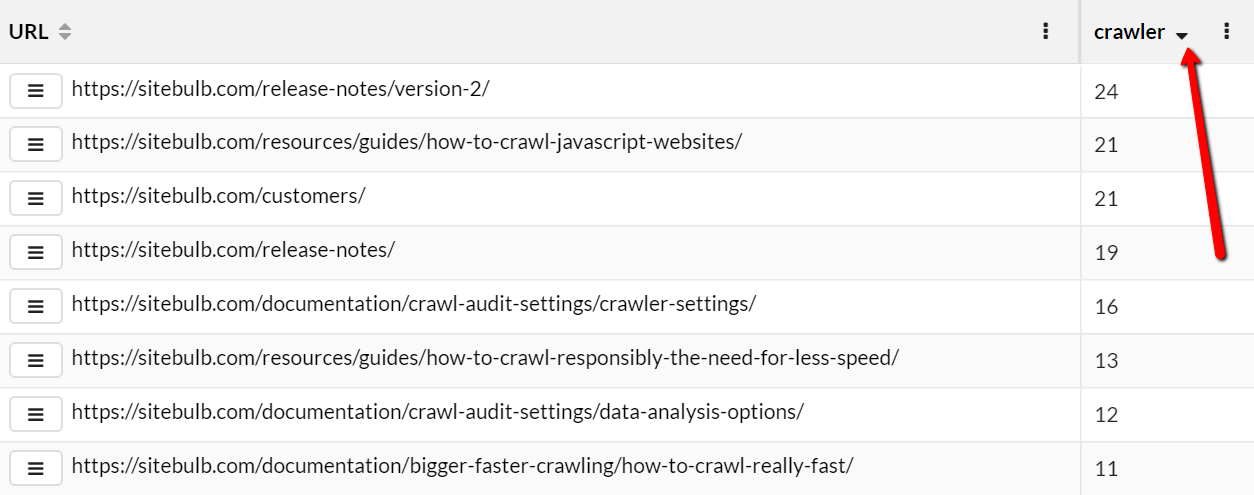
As always with URL Lists, you can add or remove columns so that you can easily combine technical crawl data with your extracted data. You can also create filters on the data to gain additional insights.
Grouping phrases
Those with a little more experience might be looking for something a little more risqué, and this is where our Advanced Content Search comes into play.
The concept is relatively straightforward, we are replacing 'word/phrase' with a combination of words to search for.
Instead of restricting yourself to only one word, why not try two or three?
Let's work through an example. Imagine we are auditing a travel website. We want to identify pages that talk about specific winter sports, so we could set it up like this:

Once this rule is applied, Sitebulb would search for any pages that contain either 'skiing', 'snowboarding' or 'ice skating' (or any combination of the three). Verifiably polyamorous.
BTW, the requirement to provide a 'Rule Name' is simply to make it easier to view the results in the report:
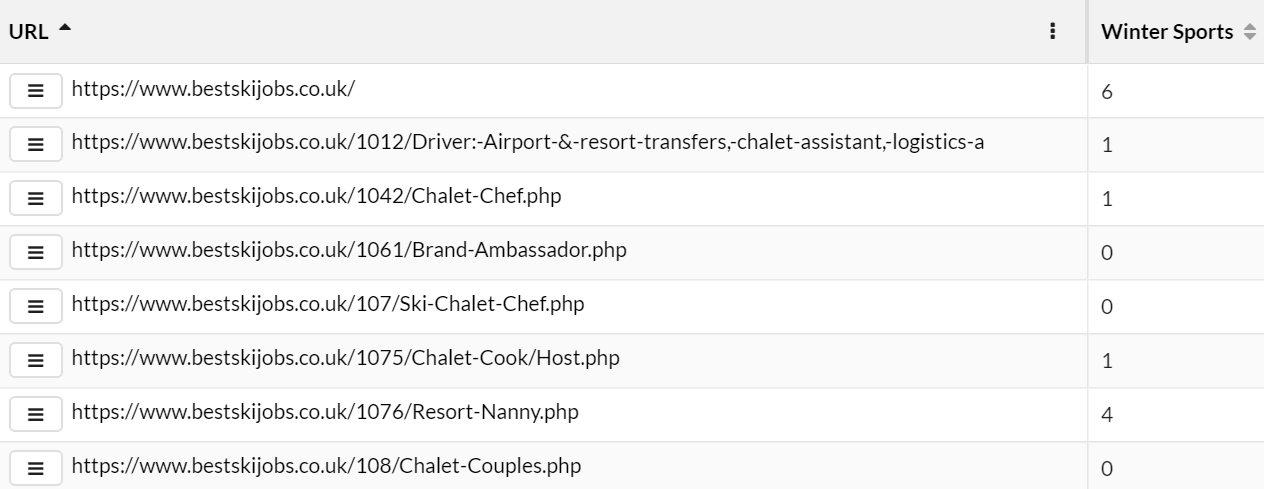
In this case, the numbers returned in the 'Winter Sports' column reflect the total number of matches. So a result of '6' might mean that 'skiing' is mentioned 4 times, 'snowboarding' 2 times and 'ice skating' not at all.
Now, imagine we wanted to identify pages that talk about specific winter sports, but only for certain countries. We could rule out specific countries by adding them in the right hand 'does not contain' box, e.g.
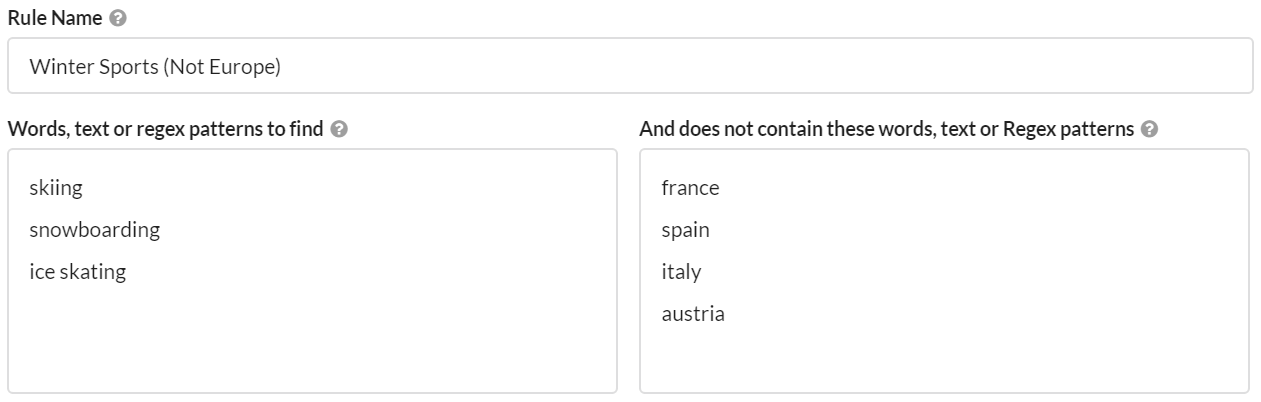
Once this rule is applied, Sitebulb would search for any pages that contain either 'skiing', 'snowboarding' or 'ice skating' (or any combination of the three) AND ALSO contain none of 'france', 'spain', 'italy' and 'austria.'
What this does is surface the pages about USA/Canada instead of Europe, as we wanted:

Using this combination approach allows you to do things like categorise pages based on topic, or group them based on a set of target keywords - which could then be used for content audits or internal linking strategies.
Updated Chromium Crawler
As per our commitment to maintaining our Chrome Crawler to be evergreen, like the Googlebot crawler, we have updated it to use the latest stable version of Chromium, version 85 (85.0.4182.0, to be precise).
Moved Code Coverage/Accessibility
With all of this new stuff we've added, we were running out of real estate on our audit setup page, it was as crowded as a crappy British beach on the only sunny day in lockdown. So, we moved some stuff around, which you might not notice if you don't read the next couple of paragraphs. Or, most likely, even if you do.
The 2 audit options we have moved are:
- Code Coverage
- Accessibility
They can now be found in Advanced Settings:
IMPORTANT NOTE: You will only find them in there when you have the Chrome Crawler selected. Otherwise you'll just be presented with a greyed out panel.
Crawl Subdomains
When we first built Sitebulb, we set out our stall to be a 'one website at a time' type of SEO tool. Other crawler tools take a different approach, but we were happy to be different. We would proudly declare that you can only ever crawl one subdomain at a time with Sitebulb, as each different subdomain should be considered a website in and of itself.
We stubbornly clung to this philosophy, even when it was becoming abundantly clear that we were wrong.
Sometimes you genuinely do encounter a site that has been set up with subdomains so tangled and deeply intertwined in the architecture that it becomes impossible to know where one ends and the other begins. Like institutional racism.
But wrong we were, and so fix it we have. You can now navigate to advanced settings and set up Sitebulb to crawl subdomains.
In Advanced Settings, the Subdomains section is under Crawler -> Subdomains
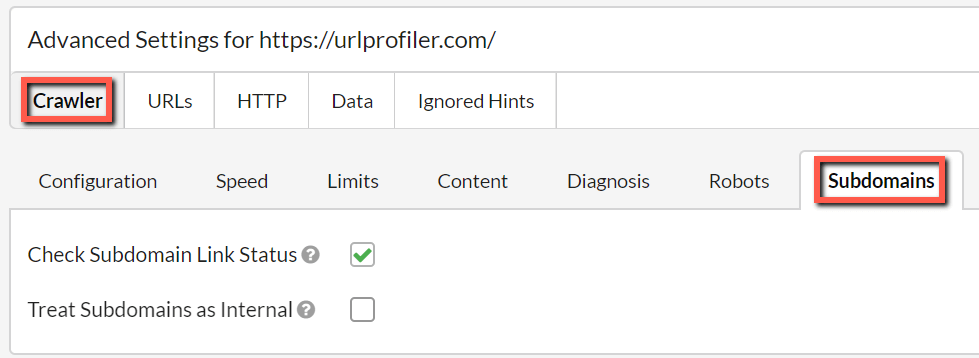
What you need to do is tick the second box here: 'Treat Subdomains as Internal' - this means that any subdomain URLs that Sitebulb encounters will be treated as internal URLs. On other words, ticking this box is 'how to crawl all subdomain URLs on a website'. Sitebulb will run all the normal 'internal checks' on these URLs, including internal link calculations.
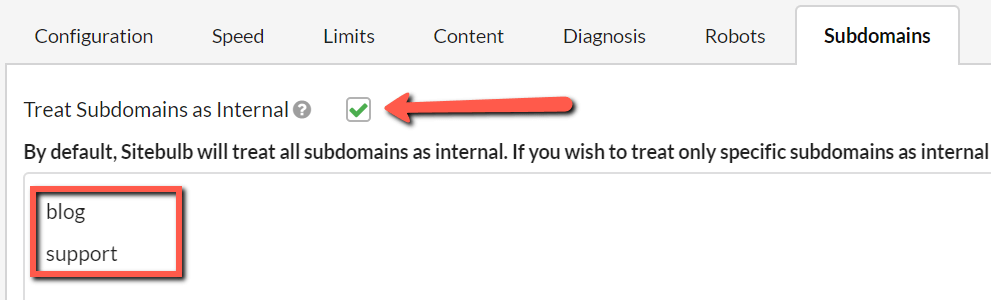
When you do tick the box, you will be now faced with the option of explicitly adding the subdomains, one per line in the box underneath.
If you tick the box and don't add any subdomains into the box, ALL subdomain URLs will be crawled. However if you do add some subdomains to the box, ONLY those subdomains will be crawled.
Simply enter the subdomains, one per line. In the example below, Sitebulb would crawl https://blog.example.com and https://support.example.com and treat those subdomains as internal (but NOT https://community.example.com or any other subdomain).
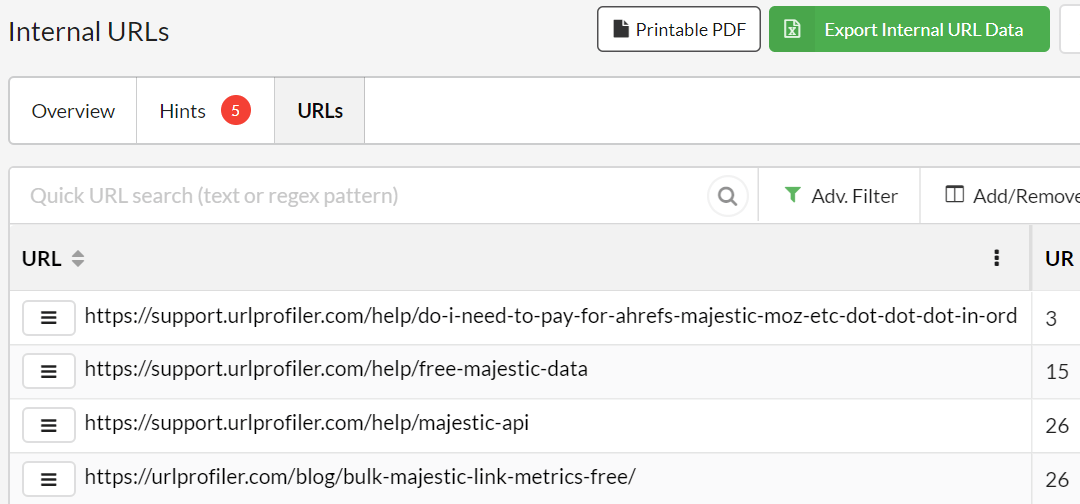
When you come to look at the completed audit results, you will see that URLs from subdomains will now appear in the 'Internal URLs' lists, and they will have URL Rank (UR) scores.
Similarity % added to Similar Content check
We know we do a lot of updates. Some users even say it is annoying. But we are (normally) giving you lots of new stuff to play with. Anyway, because of this, sometimes we fear that stuff gets missed.
Take 'Similar Content' (AKA 'Near Duplicate Content') - we added this way back in October last year, but it feels like nobody noticed it.
But I'm not mad about it.
Instead, we'll just focus your attention by improving the feature, giving me another opportunity to get out my drum and bang on about it again.
You'll find Similar Content in the Duplicate Content graph (where it has always been), and also in the Duplicate Content Hints.
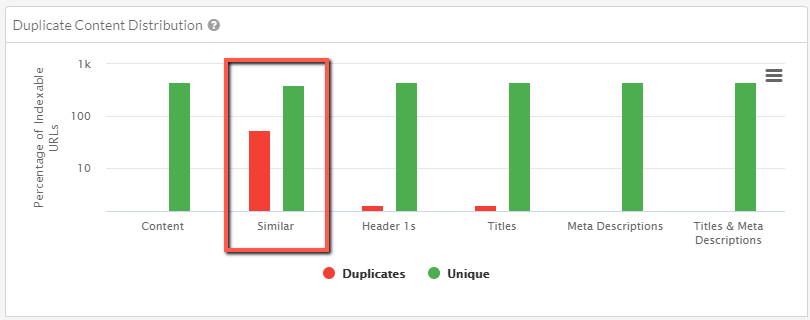
Now, when you click through from this chart to view the data, you'll see a new column 'Closest Similarity.' This metric allows you to understand where you have the biggest 'problems' in terms of similar content.
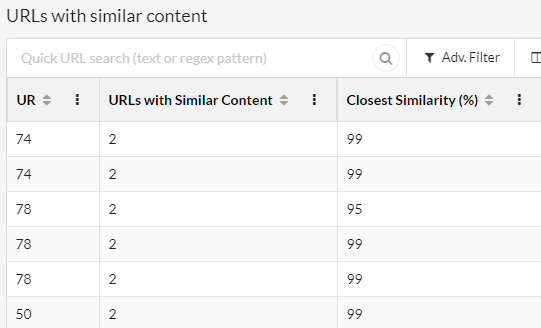
Figuring out which specific URLs are similar is also a piece of cake, just click the URL Details and view the Duplicate Content tab.
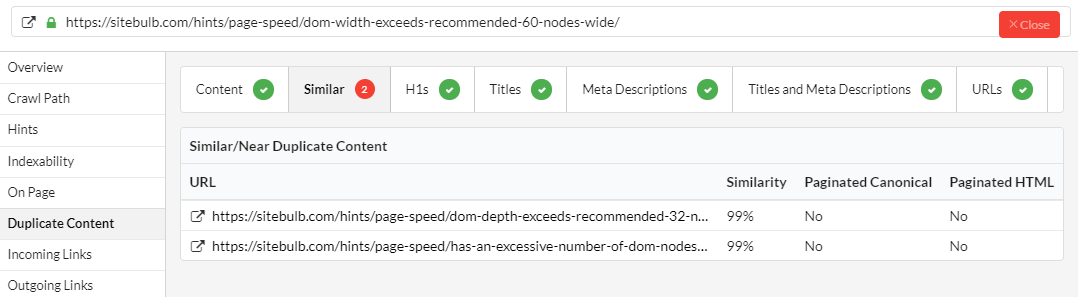
As always, you can just export the bulk data to CSV or to Google Sheets with a press of a button, if you'd rather analyse it in a spreadsheet.
Since I finally have your attention in this regard (I'm not mad about it), I thought I might share some technical details about how Sitebulb calculates similar content.
Firstly, similar content is flagged as standard, it's not a configuration option you need to turn on. Secondly, you don't need to worry about specifying content areas - Sitebulb already 'dechromes' each page of its navigational elements, then minhashes the remaining content. This means you don't need to worry about having different page templates and specifying the content area for each (which we feel is likely similar to how a search engine would handle the content).
Finally, the new similarity figure is detected using a Jaccard similarity algorithm. Here's some further reading on the topic if you would be so inclined.
Although I'm sure that you won't be. I expect I lost you at 'updates.'
But I'm not that mad about it.
Mark Hints as Fixed
Lots of users like to treat Sitebulb's Hints as a checklist, before diving deeper into other issues.
To aid such a process, we have added the option to mark a given Hint as 'Fixed.' Now, it need not literally be fixed, you could check it off simply because you have already investigated it and deemed it not a problem.
Frankly, you can do with it as you damn well like.
Now, every Hint has a 'Mark as Fixed' button on the right hand side:

If you wish to mark a Hint as fixed, simply click that button, optionally add a comment, and then 'Tick':

You will see a green 'Fixed' box appear in the top right hand corner of the Hint. Hover over this green box in order to see the comment.
Moving forwards, this Hint will remain 'Fixed' within this Audit. So if you navigate into a different Audit or Project, and return to this Audit, the Hint will still be 'Fixed'.
Similarly, in other areas of the Audit, such as the 'All Hints' page, the 'Fixed' designation will carry through, for any Hints you have marked as fixed.

There are two important things to note regarding this functionality:
- Marking a Hint as 'Fixed' does not alter any of the audit scores. It is designed simply to be a mechanism for marking items as done.
- The 'Fixed' designation only applies to this single Audit. If you run future Audits on the same website, none of the Hints will be marked as fixed.
As a follow-up to #2 above, you may instead wish to 'Ignore' certain Hints, which is handled by slightly different functionality - read about ignoring Hints below. It might be prudent to prepare yourself in advance for my scathing tone.
Ignore Hints
In general, we receive a lot of plaudits for our Hints. Our customers seem to think they are useful, and help them do their jobs more efficiently. We spent hundreds of hours lovingly crafting them for your consumption: coding them, scoring them, and writing up their 'How to fix' pages.
Yet.
Every once in a while, a customer will approach us and say things like 'I hate this Hint, can't I just ignore it?'
Up to now, our reaction has always been, 'Fuck off, you ungrateful bastard.'
And whilst this sentiment still remains, now we actually let you do it. And no, before you ask, I'm not going to demo it here; because, frankly, I'm still a bit pissed off that you asked for it in the first place. You can make do with an unordered list.
Ignoring Hints can be controlled in two places:
- Advanced Settings - this allows you to ignore Hints for a specific Audit/Project.
- Global Settings - this allows you to ignore Hints for ALL future Audits/Projects.
Follow the links if you really want to know more.
Now get out.
Fixes
- On sites with hreflang that utilised x-default, the x-default value was causing a conflict, so Sitebulb would report the page as having no hreflang at all.
- The Security checks were not detecting when TLS 1.3 was enabled on a server. Which is somewhat counter-intuitive.
- The mixed content export was all coming out on a single row.
- Scaled images Hint was not firing on certain pages that had scaled images. The code wasn't checking the data-src attribute and bypassing the check.
- <picture> image references in HTML were being reported as 404s.
- A specific HTML formatting issue was causing <h1> tags to be classed as 'missing' by Sitebulb when they were actually there.
Archives
Access the archives of Sitebulb's Release Notes, to explore the development of this precocious young upstart:
- The Beta Notes (January-September 2017)
- Version 1 (September 2017 - March 2018)
- Version 2 (April 2018 - May 2019)
- Version 3 (October 2019 - July 2020)